{"title":"Enhancing spoken dialect identification with stacked generalization of deep learning models","authors":"Khaled Lounnas, Mohamed Lichouri, Mourad Abbas","doi":"10.1007/s11042-024-20143-9","DOIUrl":null,"url":null,"abstract":"<p>As dialects are widely used in many countries, there is growing interest in incorporating them into various applications, including conversational systems. Processing spoken dialects is an important module in such systems, yet it remains a challenging task due to the lack of resources and the inherent ambiguity and complexity of dialects. This paper presents a comparison of two approaches for identifying spoken Maghrebi dialects, tested on an in-house corpus composed of four dialects: Algerian Arabic Dialect (AAD), Algerian Berber Dialect (ABD), Moroccan Arabic Dialect (MAD), and Moroccan Berber Dialect (MBD), as well as two variants of Modern Standard Arabic (MSA): MSA_ALG and MSA_MAR. The first method uses a fully connected neural network (NN2) to retrain several Transfer Learning (TL) models with varying layer numbers, including Residual Networks (ResNet50, ResNet101), Visual Geometric Group networks (VGG16, VGG19), Dense Convolutional Networks (DenseNet121, DenseNet169), and Efficient Convolutional Neural Networks for Mobile Vision Applications (MobileNet, MobileNetV2). These models were chosen based on their proven ability to capture different levels of feature abstraction: deeper models like ResNet and DenseNet are capable of capturing more complex and nuanced patterns, which is critical for distinguishing subtle differences in dialects, while VGG and MobileNet models offer computational efficiency, making them suitable for applications with limited resources. The second approach employs a “stacked generalization” strategy, which merges predictions from the previously trained models to enhance the final classification performance. Our results show that this cascade strategy improves the overall performance of the Language/Dialect Identification system, with an accuracy increase of up to 5% for specific dialect pairs. Notably, the best performance was achieved with DenseNet and ResNet models, reaching an accuracy of 99.11% for distinguishing between Algerian Berber Dialect and Moroccan Berber Dialect. These findings indicate that despite the limited size of the employed dataset, the cascade strategy and the selection of robust TL models significantly enhance the system’s performance in dialect identification. By leveraging the unique strengths of each model, our approach demonstrates a robust and efficient solution to the challenge of spoken dialect processing.</p>","PeriodicalId":18770,"journal":{"name":"Multimedia Tools and Applications","volume":"35 1","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-09-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Tools and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11042-024-20143-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
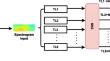
As dialects are widely used in many countries, there is growing interest in incorporating them into various applications, including conversational systems. Processing spoken dialects is an important module in such systems, yet it remains a challenging task due to the lack of resources and the inherent ambiguity and complexity of dialects. This paper presents a comparison of two approaches for identifying spoken Maghrebi dialects, tested on an in-house corpus composed of four dialects: Algerian Arabic Dialect (AAD), Algerian Berber Dialect (ABD), Moroccan Arabic Dialect (MAD), and Moroccan Berber Dialect (MBD), as well as two variants of Modern Standard Arabic (MSA): MSA_ALG and MSA_MAR. The first method uses a fully connected neural network (NN2) to retrain several Transfer Learning (TL) models with varying layer numbers, including Residual Networks (ResNet50, ResNet101), Visual Geometric Group networks (VGG16, VGG19), Dense Convolutional Networks (DenseNet121, DenseNet169), and Efficient Convolutional Neural Networks for Mobile Vision Applications (MobileNet, MobileNetV2). These models were chosen based on their proven ability to capture different levels of feature abstraction: deeper models like ResNet and DenseNet are capable of capturing more complex and nuanced patterns, which is critical for distinguishing subtle differences in dialects, while VGG and MobileNet models offer computational efficiency, making them suitable for applications with limited resources. The second approach employs a “stacked generalization” strategy, which merges predictions from the previously trained models to enhance the final classification performance. Our results show that this cascade strategy improves the overall performance of the Language/Dialect Identification system, with an accuracy increase of up to 5% for specific dialect pairs. Notably, the best performance was achieved with DenseNet and ResNet models, reaching an accuracy of 99.11% for distinguishing between Algerian Berber Dialect and Moroccan Berber Dialect. These findings indicate that despite the limited size of the employed dataset, the cascade strategy and the selection of robust TL models significantly enhance the system’s performance in dialect identification. By leveraging the unique strengths of each model, our approach demonstrates a robust and efficient solution to the challenge of spoken dialect processing.
期刊介绍:
Multimedia Tools and Applications publishes original research articles on multimedia development and system support tools as well as case studies of multimedia applications. It also features experimental and survey articles. The journal is intended for academics, practitioners, scientists and engineers who are involved in multimedia system research, design and applications. All papers are peer reviewed.
Specific areas of interest include:
- Multimedia Tools:
- Multimedia Applications:
- Prototype multimedia systems and platforms

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


