{"title":"Transformer with multi-level grid features and depth pooling for image captioning","authors":"Doanh C. Bui, Tam V. Nguyen, Khang Nguyen","doi":"10.1007/s00138-024-01599-z","DOIUrl":null,"url":null,"abstract":"<p>Image captioning is an exciting yet challenging problem in both computer vision and natural language processing research. In recent years, this problem has been addressed by Transformer-based models optimized with Cross-Entropy loss and boosted performance via Self-Critical Sequence Training. Two types of representations are embedded into captioning models: grid features and region features, and there have been attempts to include 2D geometry information in the self-attention computation. However, the 3D order of object appearances is not considered, leading to confusion for the model in cases of complex scenes with overlapped objects. In addition, recent studies using only feature maps from the last layer or block of a pretrained CNN-based model may lack spatial information. In this paper, we present the Transformer-based captioning model dubbed TMDNet. Our model includes one module to aggregate multi-level grid features (MGFA) to enrich the representation ability using prior knowledge, and another module to effectively embed the image’s depth-grid aggregation (DGA) into the model space for better performance. The proposed model demonstrates its effectiveness via evaluation on the MS-COCO “Karpathy” test split across five standard metrics.\n</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"9 1","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-08-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-024-01599-z","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
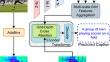
Image captioning is an exciting yet challenging problem in both computer vision and natural language processing research. In recent years, this problem has been addressed by Transformer-based models optimized with Cross-Entropy loss and boosted performance via Self-Critical Sequence Training. Two types of representations are embedded into captioning models: grid features and region features, and there have been attempts to include 2D geometry information in the self-attention computation. However, the 3D order of object appearances is not considered, leading to confusion for the model in cases of complex scenes with overlapped objects. In addition, recent studies using only feature maps from the last layer or block of a pretrained CNN-based model may lack spatial information. In this paper, we present the Transformer-based captioning model dubbed TMDNet. Our model includes one module to aggregate multi-level grid features (MGFA) to enrich the representation ability using prior knowledge, and another module to effectively embed the image’s depth-grid aggregation (DGA) into the model space for better performance. The proposed model demonstrates its effectiveness via evaluation on the MS-COCO “Karpathy” test split across five standard metrics.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


