{"title":"Distilling OCT cervical dataset with evidential uncertainty proxy","authors":"Yuxuan Xiong , Yongchao Xu , Yan Zhang , Bo Du","doi":"10.1016/j.imavis.2024.105250","DOIUrl":null,"url":null,"abstract":"<div><p>Deep learning-based OCT image classification method is of paramount importance for early screening of cervical cancer. For the sake of efficiency and privacy, the emerging data distillation technique becomes a promising way to condense the large-scale original OCT dataset into a much smaller synthetic dataset, without losing much information for network training. However, OCT cervical images often suffer from redundancy, mis-operation and noise, <em>etc.</em> These challenges make it hard to compress as much valuable information as possible into extremely small synthesized dataset. To this end, we design an uncertainty-aware distribution matching based dataset distillation framework (UDM). Precisely, we adopt a pre-trained plug-and-play uncertainty estimation proxy to compute classification uncertainty for each data point in the original and synthetic dataset. The estimated uncertainty allows us to adaptively calculate class-wise feature centers of the original and synthetic data, thereby increasing the importance of typical patterns and reducing the impact of redundancy, mis-operation, and noise, <em>etc.</em> Extensive experiments show that our UDM effectively improves distribution-matching-based dataset distillation under both homogeneous and heterogeneous training scenarios.</p></div>","PeriodicalId":50374,"journal":{"name":"Image and Vision Computing","volume":"151 ","pages":"Article 105250"},"PeriodicalIF":4.2000,"publicationDate":"2024-09-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Image and Vision Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S026288562400355X","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
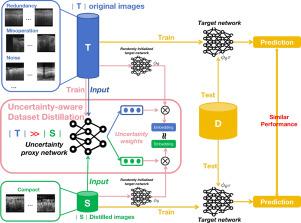
Deep learning-based OCT image classification method is of paramount importance for early screening of cervical cancer. For the sake of efficiency and privacy, the emerging data distillation technique becomes a promising way to condense the large-scale original OCT dataset into a much smaller synthetic dataset, without losing much information for network training. However, OCT cervical images often suffer from redundancy, mis-operation and noise, etc. These challenges make it hard to compress as much valuable information as possible into extremely small synthesized dataset. To this end, we design an uncertainty-aware distribution matching based dataset distillation framework (UDM). Precisely, we adopt a pre-trained plug-and-play uncertainty estimation proxy to compute classification uncertainty for each data point in the original and synthetic dataset. The estimated uncertainty allows us to adaptively calculate class-wise feature centers of the original and synthetic data, thereby increasing the importance of typical patterns and reducing the impact of redundancy, mis-operation, and noise, etc. Extensive experiments show that our UDM effectively improves distribution-matching-based dataset distillation under both homogeneous and heterogeneous training scenarios.
基于深度学习的 OCT 图像分类方法对于宫颈癌的早期筛查至关重要。为了提高效率和保护隐私,新兴的数据蒸馏技术成为一种很有前景的方法,它能将大规模的原始 OCT 数据集浓缩为更小的合成数据集,同时不会丢失太多用于网络训练的信息。然而,OCT 颈椎图像往往存在冗余、误操作和噪声等问题。这些挑战使得我们很难将尽可能多的有价值信息压缩到极小的合成数据集中。为此,我们设计了一种基于不确定性感知分布匹配的数据集提炼框架(UDM)。确切地说,我们采用了一个预先训练好的即插即用不确定性估计代理,来计算原始数据集和合成数据集中每个数据点的分类不确定性。通过估计不确定性,我们可以自适应地计算原始数据和合成数据的分类特征中心,从而提高典型模式的重要性,减少冗余、误操作和噪声等的影响。大量实验表明,无论是在同质还是异质训练场景下,我们的 UDM 都能有效改进基于分布匹配的数据集提炼。
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


