{"title":"Distilling BERT knowledge into Seq2Seq with regularized Mixup for low-resource neural machine translation","authors":"Guanghua Zhang , Hua Liu , Junjun Guo , Tianyu Guo","doi":"10.1016/j.eswa.2024.125314","DOIUrl":null,"url":null,"abstract":"<div><p>Pre-trained language models, such as Bidirectional Encoder Representations from Transformers (BERT), have demonstrated state-of-the-art performance in many Natural Language Processing (NLP) downstream tasks. Incorporating pre-trained BERT knowledge into the Sequence-to-Sequence (Seq2Seq) model can significantly enhance machine translation performance, particularly for low-resource language pairs. However, most previous studies prefer to fine-tune both the large pre-trained BERT model and the Seq2Seq model jointly, leading to costly training times, especially with limited parallel data pairs. Consequently, the integration of pre-trained BERT contextual representations into the Seq2Seq framework is limited. In this paper, we propose a simple and effective BERT knowledge fusion approach based on regularized Mixup for low-resource Neural Machine Translation (NMT), referred to as ReMixup-NMT, which constrains the distributions of the normal Transformer encoder and the Mixup-based Transformer encoder to be consistent. The proposed ReMixup NMT approach is able to distill and fuse the pre-trained BERT knowledge into Seq2Seq NMT architecture in an efficient manner with non-additional parameters training. Experiment results on six low-resource NMT tasks show the proposed approach outperforms the state-of-the-art (SOTA) BERT-fused and drop-based methods on IWSLT’15 English<span><math><mo>→</mo></math></span>Vietnamese and IWSLT’17 English<span><math><mo>→</mo></math></span>French datasets.</p></div>","PeriodicalId":50461,"journal":{"name":"Expert Systems with Applications","volume":"259 ","pages":"Article 125314"},"PeriodicalIF":7.5000,"publicationDate":"2024-09-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Expert Systems with Applications","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S095741742402181X","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
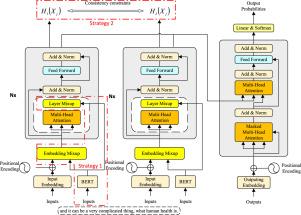
Pre-trained language models, such as Bidirectional Encoder Representations from Transformers (BERT), have demonstrated state-of-the-art performance in many Natural Language Processing (NLP) downstream tasks. Incorporating pre-trained BERT knowledge into the Sequence-to-Sequence (Seq2Seq) model can significantly enhance machine translation performance, particularly for low-resource language pairs. However, most previous studies prefer to fine-tune both the large pre-trained BERT model and the Seq2Seq model jointly, leading to costly training times, especially with limited parallel data pairs. Consequently, the integration of pre-trained BERT contextual representations into the Seq2Seq framework is limited. In this paper, we propose a simple and effective BERT knowledge fusion approach based on regularized Mixup for low-resource Neural Machine Translation (NMT), referred to as ReMixup-NMT, which constrains the distributions of the normal Transformer encoder and the Mixup-based Transformer encoder to be consistent. The proposed ReMixup NMT approach is able to distill and fuse the pre-trained BERT knowledge into Seq2Seq NMT architecture in an efficient manner with non-additional parameters training. Experiment results on six low-resource NMT tasks show the proposed approach outperforms the state-of-the-art (SOTA) BERT-fused and drop-based methods on IWSLT’15 EnglishVietnamese and IWSLT’17 EnglishFrench datasets.
期刊介绍:
Expert Systems With Applications is an international journal dedicated to the exchange of information on expert and intelligent systems used globally in industry, government, and universities. The journal emphasizes original papers covering the design, development, testing, implementation, and management of these systems, offering practical guidelines. It spans various sectors such as finance, engineering, marketing, law, project management, information management, medicine, and more. The journal also welcomes papers on multi-agent systems, knowledge management, neural networks, knowledge discovery, data mining, and other related areas, excluding applications to military/defense systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


