Efficient and scalable reinforcement learning for large-scale network control
IF 18.8
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
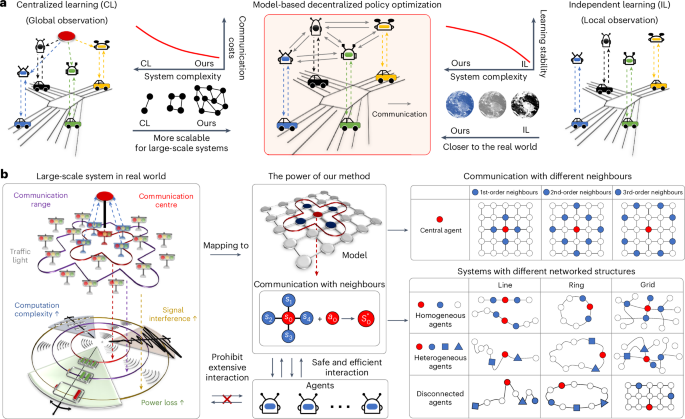
The primary challenge in the development of large-scale artificial intelligence (AI) systems lies in achieving scalable decision-making—extending the AI models while maintaining sufficient performance. Existing research indicates that distributed AI can improve scalability by decomposing complex tasks and distributing them across collaborative nodes. However, previous technologies suffered from compromised real-world applicability and scalability due to the massive requirement of communication and sampled data. Here we develop a model-based decentralized policy optimization framework, which can be efficiently deployed in multi-agent systems. By leveraging local observation through the agent-level topological decoupling of global dynamics, we prove that this decentralized mechanism achieves accurate estimations of global information. Importantly, we further introduce model learning to reinforce the optimal policy for monotonic improvement with a limited amount of sampled data. Empirical results on diverse scenarios show the superior scalability of our approach, particularly in real-world systems with hundreds of agents, thereby paving the way for scaling up AI systems. Applying large-scale AI systems to multi-agent scenarios in real-world settings is challenging. The authors propose a decentralized model-based policy optimization framework to enable scalable decision-making.
用于大规模网络控制的高效可扩展强化学习
开发大规模人工智能(AI)系统的主要挑战在于实现可扩展决策--在扩展人工智能模型的同时保持足够的性能。现有研究表明,分布式人工智能可以通过分解复杂任务并将其分配到协作节点来提高可扩展性。然而,由于需要大量的通信和采样数据,以前的技术在现实世界中的适用性和可扩展性大打折扣。在这里,我们开发了一种基于模型的分散式策略优化框架,可以高效地部署在多代理系统中。通过全局动态的代理级拓扑解耦利用局部观察,我们证明了这种分散机制可以实现对全局信息的精确估计。重要的是,我们进一步引入了模型学习,以强化最优策略,从而在采样数据量有限的情况下实现单调改进。在不同场景下的实证结果表明,我们的方法具有卓越的可扩展性,尤其是在拥有数百个代理的真实世界系统中,从而为人工智能系统的扩展铺平了道路。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


