Tiange Liu , Qingze Bai , Drew A. Torigian , Yubing Tong , Jayaram K. Udupa
{"title":"VSmTrans: A hybrid paradigm integrating self-attention and convolution for 3D medical image segmentation","authors":"Tiange Liu , Qingze Bai , Drew A. Torigian , Yubing Tong , Jayaram K. Udupa","doi":"10.1016/j.media.2024.103295","DOIUrl":null,"url":null,"abstract":"<div><h3>Purpose</h3><p>Vision Transformers recently achieved a competitive performance compared with CNNs due to their excellent capability of learning global representation. However, there are two major challenges when applying them to 3D image segmentation: i) Because of the large size of 3D medical images, comprehensive global information is hard to capture due to the enormous computational costs. ii) Insufficient local inductive bias in Transformers affects the ability to segment detailed features such as ambiguous and subtly defined boundaries. Hence, to apply the Vision Transformer mechanism in the medical image segmentation field, the above challenges need to be overcome adequately.</p></div><div><h3>Methods</h3><p>We propose a hybrid paradigm, called Variable-Shape Mixed Transformer (VSmTrans), that integrates self-attention and convolution and can enjoy the benefits of free learning of both complex relationships from the self-attention mechanism and the local prior knowledge from convolution. Specifically, we designed a Variable-Shape self-attention mechanism, which can rapidly expand the receptive field without extra computing cost and achieve a good trade-off between global awareness and local details. In addition, the parallel convolution paradigm introduces strong local inductive bias to facilitate the ability to excavate details. Meanwhile, a pair of learnable parameters can automatically adjust the importance of the above two paradigms. Extensive experiments were conducted on two public medical image datasets with different modalities: the AMOS CT dataset and the BraTS2021 MRI dataset.</p></div><div><h3>Results</h3><p>Our method achieves the best average Dice scores of 88.3 % and 89.7 % on these datasets, which are superior to the previous state-of-the-art Swin Transformer-based and CNN-based architectures. A series of ablation experiments were also conducted to verify the efficiency of the proposed hybrid mechanism and the components and explore the effectiveness of those key parameters in VSmTrans.</p></div><div><h3>Conclusions</h3><p>The proposed hybrid Transformer-based backbone network for 3D medical image segmentation can tightly integrate self-attention and convolution to exploit the advantages of these two paradigms. The experimental results demonstrate our method's superiority compared to other state-of-the-art methods. The hybrid paradigm seems to be most appropriate to the medical image segmentation field. The ablation experiments also demonstrate that the proposed hybrid mechanism can effectively balance large receptive fields with local inductive biases, resulting in highly accurate segmentation results, especially in capturing details. Our code is available at https://github.com/qingze-bai/VSmTrans.</p></div>","PeriodicalId":18328,"journal":{"name":"Medical image analysis","volume":"98 ","pages":"Article 103295"},"PeriodicalIF":11.8000,"publicationDate":"2024-08-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical image analysis","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1361841524002202","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose
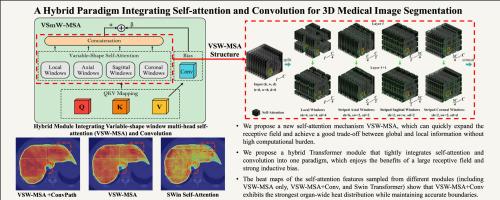
Vision Transformers recently achieved a competitive performance compared with CNNs due to their excellent capability of learning global representation. However, there are two major challenges when applying them to 3D image segmentation: i) Because of the large size of 3D medical images, comprehensive global information is hard to capture due to the enormous computational costs. ii) Insufficient local inductive bias in Transformers affects the ability to segment detailed features such as ambiguous and subtly defined boundaries. Hence, to apply the Vision Transformer mechanism in the medical image segmentation field, the above challenges need to be overcome adequately.
Methods
We propose a hybrid paradigm, called Variable-Shape Mixed Transformer (VSmTrans), that integrates self-attention and convolution and can enjoy the benefits of free learning of both complex relationships from the self-attention mechanism and the local prior knowledge from convolution. Specifically, we designed a Variable-Shape self-attention mechanism, which can rapidly expand the receptive field without extra computing cost and achieve a good trade-off between global awareness and local details. In addition, the parallel convolution paradigm introduces strong local inductive bias to facilitate the ability to excavate details. Meanwhile, a pair of learnable parameters can automatically adjust the importance of the above two paradigms. Extensive experiments were conducted on two public medical image datasets with different modalities: the AMOS CT dataset and the BraTS2021 MRI dataset.
Results
Our method achieves the best average Dice scores of 88.3 % and 89.7 % on these datasets, which are superior to the previous state-of-the-art Swin Transformer-based and CNN-based architectures. A series of ablation experiments were also conducted to verify the efficiency of the proposed hybrid mechanism and the components and explore the effectiveness of those key parameters in VSmTrans.
Conclusions
The proposed hybrid Transformer-based backbone network for 3D medical image segmentation can tightly integrate self-attention and convolution to exploit the advantages of these two paradigms. The experimental results demonstrate our method's superiority compared to other state-of-the-art methods. The hybrid paradigm seems to be most appropriate to the medical image segmentation field. The ablation experiments also demonstrate that the proposed hybrid mechanism can effectively balance large receptive fields with local inductive biases, resulting in highly accurate segmentation results, especially in capturing details. Our code is available at https://github.com/qingze-bai/VSmTrans.
期刊介绍:
Medical Image Analysis serves as a platform for sharing new research findings in the realm of medical and biological image analysis, with a focus on applications of computer vision, virtual reality, and robotics to biomedical imaging challenges. The journal prioritizes the publication of high-quality, original papers contributing to the fundamental science of processing, analyzing, and utilizing medical and biological images. It welcomes approaches utilizing biomedical image datasets across all spatial scales, from molecular/cellular imaging to tissue/organ imaging.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


