A large-scale audit of dataset licensing and attribution in AI
IF 18.8
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
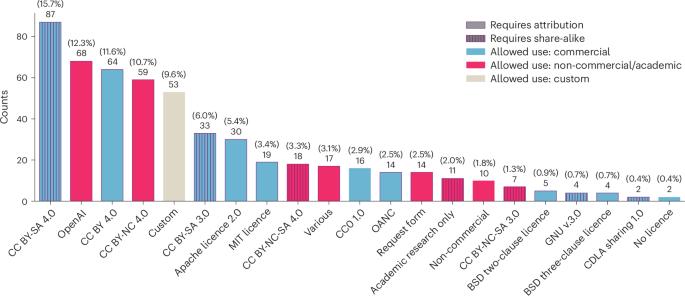
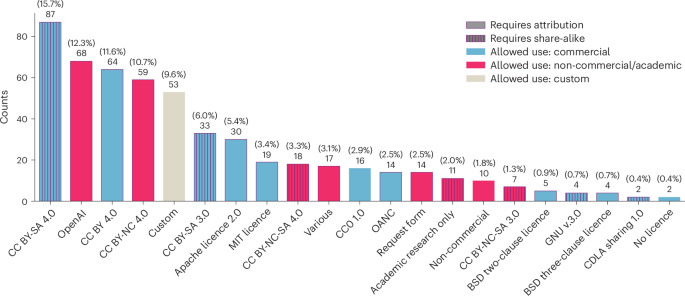
The race to train language models on vast, diverse and inconsistently documented datasets raises pressing legal and ethical concerns. To improve data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace more than 1,800 text datasets. We develop tools and standards to trace the lineage of these datasets, including their source, creators, licences and subsequent use. Our landscape analysis highlights sharp divides in the composition and focus of data licenced for commercial use. Important categories including low-resource languages, creative tasks and new synthetic data all tend to be restrictively licenced. We observe frequent miscategorization of licences on popular dataset hosting sites, with licence omission rates of more than 70% and error rates of more than 50%. This highlights a crisis in misattribution and informed use of popular datasets driving many recent breakthroughs. Our analysis of data sources also explains the application of copyright law and fair use to finetuning data. As a contribution to continuing improvements in dataset transparency and responsible use, we release our audit, with an interactive user interface, the Data Provenance Explorer, to enable practitioners to trace and filter on data provenance for the most popular finetuning data collections: www.dataprovenance.org . The Data Provenance Initiative audits over 1,800 text artificial intelligence (AI) datasets, analysing trends, permissions of use and global representation. It exposes frequent errors on several major data hosting sites and offers tools for transparent and informed use of AI training data.
对人工智能中的数据集许可和归属进行大规模审计
在庞大、多样且记录不一致的数据集上训练语言模型的竞赛引发了紧迫的法律和道德问题。为了提高数据的透明度和理解度,我们召集了法律和机器学习专家开展多学科合作,对 1800 多个文本数据集进行系统审核和追踪。我们开发了各种工具和标准来追踪这些数据集的源流,包括它们的来源、创建者、许可证和后续使用情况。我们的分析结果表明,获得商业使用许可的数据在构成和重点方面存在明显差异。包括低资源语言、创造性任务和新合成数据在内的重要类别都倾向于采用限制性许可。我们观察到,在流行的数据集托管网站上,许可证经常被错误归类,许可证遗漏率超过 70%,错误率超过 50%。这凸显了在错误归类和知情使用流行数据集方面存在的危机,而这正是近期许多突破性进展的驱动力。我们对数据源的分析还解释了版权法和合理使用在数据微调中的应用。作为对持续提高数据集透明度和负责任使用的贡献,我们发布了带有交互式用户界面的数据出处资源管理器(Data Provenance Explorer)的审计报告,使从业人员能够追踪和过滤最流行的微调数据集的数据出处:www.dataprovenance.org 。数据出处倡议 "对1800多个人工智能(AI)文本数据集进行审计,分析趋势、使用权限和全球代表性。它揭露了几个主要数据托管网站上经常出现的错误,并为透明、知情地使用人工智能训练数据提供了工具。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


