David Soong, Sriram Sridhar, Han Si, Jan-Samuel Wagner, Ana Caroline Costa Sá, Christina Y Yu, Kubra Karagoz, Meijian Guan, Sanyam Kumar, Hisham Hamadeh, Brandon W Higgs
{"title":"Improving accuracy of GPT-3/4 results on biomedical data using a retrieval-augmented language model.","authors":"David Soong, Sriram Sridhar, Han Si, Jan-Samuel Wagner, Ana Caroline Costa Sá, Christina Y Yu, Kubra Karagoz, Meijian Guan, Sanyam Kumar, Hisham Hamadeh, Brandon W Higgs","doi":"10.1371/journal.pdig.0000568","DOIUrl":null,"url":null,"abstract":"<p><p>Large language models (LLMs) have made a significant impact on the fields of general artificial intelligence. General purpose LLMs exhibit strong logic and reasoning skills and general world knowledge but can sometimes generate misleading results when prompted on specific subject areas. LLMs trained with domain-specific knowledge can reduce the generation of misleading information (i.e. hallucinations) and enhance the precision of LLMs in specialized contexts. Training new LLMs on specific corpora however can be resource intensive. Here we explored the use of a retrieval-augmented generation (RAG) model which we tested on literature specific to a biomedical research area. OpenAI's GPT-3.5, GPT-4, Microsoft's Prometheus, and a custom RAG model were used to answer 19 questions pertaining to diffuse large B-cell lymphoma (DLBCL) disease biology and treatment. Eight independent reviewers assessed LLM responses based on accuracy, relevance, and readability, rating responses on a 3-point scale for each category. These scores were then used to compare LLM performance. The performance of the LLMs varied across scoring categories. On accuracy and relevance, the RAG model outperformed other models with higher scores on average and the most top scores across questions. GPT-4 was more comparable to the RAG model on relevance versus accuracy. By the same measures, GPT-4 and GPT-3.5 had the highest scores for readability of answers when compared to the other LLMs. GPT-4 and 3.5 also had more answers with hallucinations than the other LLMs, due to non-existent references and inaccurate responses to clinical questions. Our findings suggest that an oncology research-focused RAG model may outperform general-purpose LLMs in accuracy and relevance when answering subject-related questions. This framework can be tailored to Q&A in other subject areas. Further research will help understand the impact of LLM architectures, RAG methodologies, and prompting techniques in answering questions across different subject areas.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"3 8","pages":"e0000568"},"PeriodicalIF":7.7000,"publicationDate":"2024-08-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11338460/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000568","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
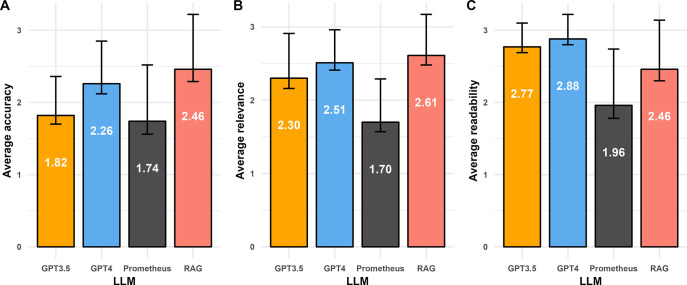
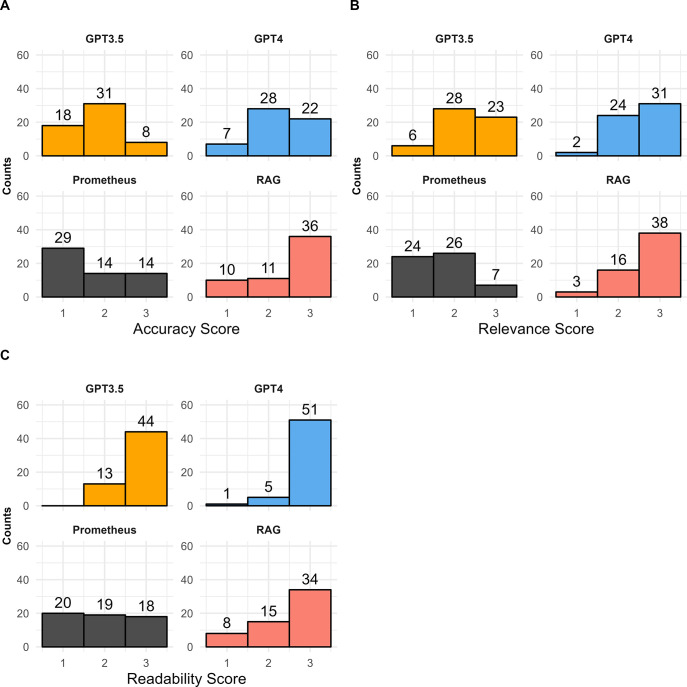
Large language models (LLMs) have made a significant impact on the fields of general artificial intelligence. General purpose LLMs exhibit strong logic and reasoning skills and general world knowledge but can sometimes generate misleading results when prompted on specific subject areas. LLMs trained with domain-specific knowledge can reduce the generation of misleading information (i.e. hallucinations) and enhance the precision of LLMs in specialized contexts. Training new LLMs on specific corpora however can be resource intensive. Here we explored the use of a retrieval-augmented generation (RAG) model which we tested on literature specific to a biomedical research area. OpenAI's GPT-3.5, GPT-4, Microsoft's Prometheus, and a custom RAG model were used to answer 19 questions pertaining to diffuse large B-cell lymphoma (DLBCL) disease biology and treatment. Eight independent reviewers assessed LLM responses based on accuracy, relevance, and readability, rating responses on a 3-point scale for each category. These scores were then used to compare LLM performance. The performance of the LLMs varied across scoring categories. On accuracy and relevance, the RAG model outperformed other models with higher scores on average and the most top scores across questions. GPT-4 was more comparable to the RAG model on relevance versus accuracy. By the same measures, GPT-4 and GPT-3.5 had the highest scores for readability of answers when compared to the other LLMs. GPT-4 and 3.5 also had more answers with hallucinations than the other LLMs, due to non-existent references and inaccurate responses to clinical questions. Our findings suggest that an oncology research-focused RAG model may outperform general-purpose LLMs in accuracy and relevance when answering subject-related questions. This framework can be tailored to Q&A in other subject areas. Further research will help understand the impact of LLM architectures, RAG methodologies, and prompting techniques in answering questions across different subject areas.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


