Comparison of machine-learning and logistic regression models for prediction of 30-day unplanned readmission in electronic health records: A development and validation study.
{"title":"Comparison of machine-learning and logistic regression models for prediction of 30-day unplanned readmission in electronic health records: A development and validation study.","authors":"Masao Iwagami, Ryota Inokuchi, Eiryo Kawakami, Tomohide Yamada, Atsushi Goto, Toshiki Kuno, Yohei Hashimoto, Nobuaki Michihata, Tadahiro Goto, Tomohiro Shinozaki, Yu Sun, Yuta Taniguchi, Jun Komiyama, Kazuaki Uda, Toshikazu Abe, Nanako Tamiya","doi":"10.1371/journal.pdig.0000578","DOIUrl":null,"url":null,"abstract":"<p><p>It is expected but unknown whether machine-learning models can outperform regression models, such as a logistic regression (LR) model, especially when the number and types of predictor variables increase in electronic health records (EHRs). We aimed to compare the predictive performance of gradient-boosted decision tree (GBDT), random forest (RF), deep neural network (DNN), and LR with the least absolute shrinkage and selection operator (LR-LASSO) for unplanned readmission. We used EHRs of patients discharged alive from 38 hospitals in 2015-2017 for derivation and in 2018 for validation, including basic characteristics, diagnosis, surgery, procedure, and drug codes, and blood-test results. The outcome was 30-day unplanned readmission. We created six patterns of data tables having different numbers of binary variables (that ≥5% or ≥1% of patients or ≥10 patients had) with and without blood-test results. For each pattern of data tables, we used the derivation data to establish the machine-learning and LR models, and used the validation data to evaluate the performance of each model. The incidence of outcome was 6.8% (23,108/339,513 discharges) and 6.4% (7,507/118,074 discharges) in the derivation and validation datasets, respectively. For the first data table with the smallest number of variables (102 variables that ≥5% of patients had, without blood-test results), the c-statistic was highest for GBDT (0.740), followed by RF (0.734), LR-LASSO (0.720), and DNN (0.664). For the last data table with the largest number of variables (1543 variables that ≥10 patients had, including blood-test results), the c-statistic was highest for GBDT (0.764), followed by LR-LASSO (0.755), RF (0.751), and DNN (0.720), suggesting that the difference between GBDT and LR-LASSO was small and their 95% confidence intervals overlapped. In conclusion, GBDT generally outperformed LR-LASSO to predict unplanned readmission, but the difference of c-statistic became smaller as the number of variables was increased and blood-test results were used.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"3 8","pages":"e0000578"},"PeriodicalIF":7.7000,"publicationDate":"2024-08-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11335098/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000578","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
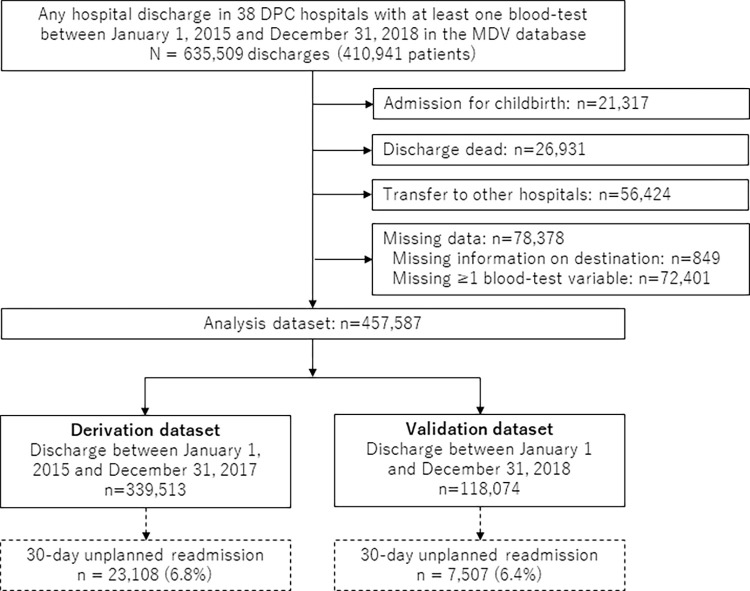
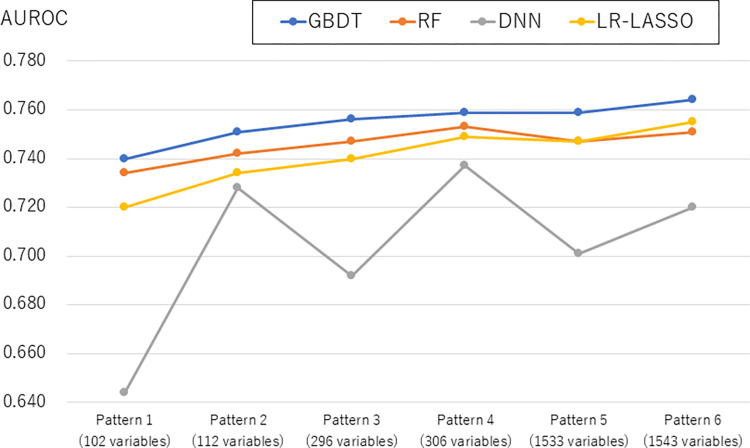
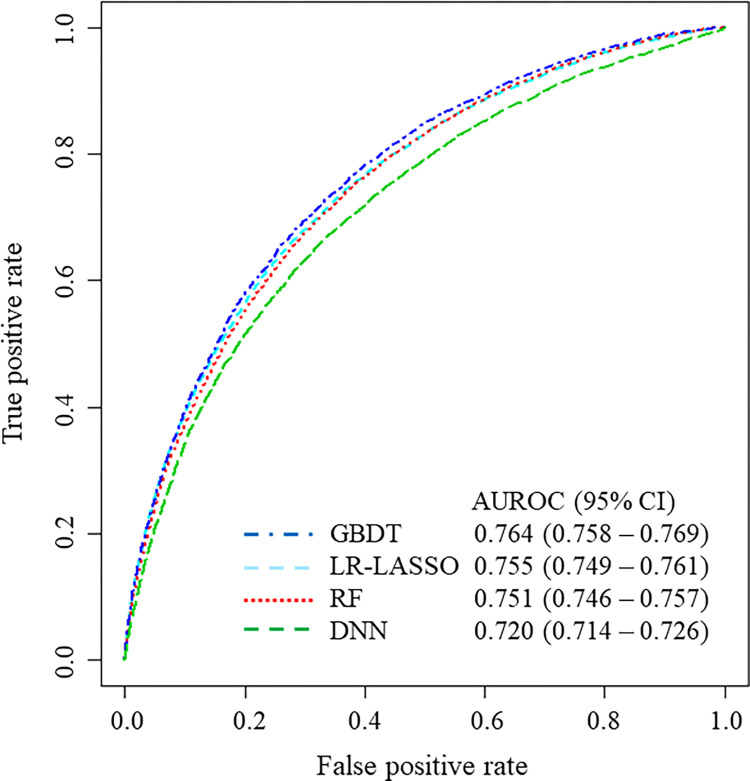
It is expected but unknown whether machine-learning models can outperform regression models, such as a logistic regression (LR) model, especially when the number and types of predictor variables increase in electronic health records (EHRs). We aimed to compare the predictive performance of gradient-boosted decision tree (GBDT), random forest (RF), deep neural network (DNN), and LR with the least absolute shrinkage and selection operator (LR-LASSO) for unplanned readmission. We used EHRs of patients discharged alive from 38 hospitals in 2015-2017 for derivation and in 2018 for validation, including basic characteristics, diagnosis, surgery, procedure, and drug codes, and blood-test results. The outcome was 30-day unplanned readmission. We created six patterns of data tables having different numbers of binary variables (that ≥5% or ≥1% of patients or ≥10 patients had) with and without blood-test results. For each pattern of data tables, we used the derivation data to establish the machine-learning and LR models, and used the validation data to evaluate the performance of each model. The incidence of outcome was 6.8% (23,108/339,513 discharges) and 6.4% (7,507/118,074 discharges) in the derivation and validation datasets, respectively. For the first data table with the smallest number of variables (102 variables that ≥5% of patients had, without blood-test results), the c-statistic was highest for GBDT (0.740), followed by RF (0.734), LR-LASSO (0.720), and DNN (0.664). For the last data table with the largest number of variables (1543 variables that ≥10 patients had, including blood-test results), the c-statistic was highest for GBDT (0.764), followed by LR-LASSO (0.755), RF (0.751), and DNN (0.720), suggesting that the difference between GBDT and LR-LASSO was small and their 95% confidence intervals overlapped. In conclusion, GBDT generally outperformed LR-LASSO to predict unplanned readmission, but the difference of c-statistic became smaller as the number of variables was increased and blood-test results were used.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


