Namkee Oh, Won Chul Cha, Jun Hyuk Seo, Seong-Gyu Choi, Jong Man Kim, Chi Ryang Chung, Gee Young Suh, Su Yeon Lee, Dong Kyu Oh, Mi Hyeon Park, Chae-Man Lim, Ryoung-Eun Ko
{"title":"ChatGPT Predicts In-Hospital All-Cause Mortality for Sepsis: In-Context Learning with the Korean Sepsis Alliance Database.","authors":"Namkee Oh, Won Chul Cha, Jun Hyuk Seo, Seong-Gyu Choi, Jong Man Kim, Chi Ryang Chung, Gee Young Suh, Su Yeon Lee, Dong Kyu Oh, Mi Hyeon Park, Chae-Man Lim, Ryoung-Eun Ko","doi":"10.4258/hir.2024.30.3.266","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Sepsis is a leading global cause of mortality, and predicting its outcomes is vital for improving patient care. This study explored the capabilities of ChatGPT, a state-of-the-art natural language processing model, in predicting in-hospital mortality for sepsis patients.</p><p><strong>Methods: </strong>This study utilized data from the Korean Sepsis Alliance (KSA) database, collected between 2019 and 2021, focusing on adult intensive care unit (ICU) patients and aiming to determine whether ChatGPT could predict all-cause mortality after ICU admission at 7 and 30 days. Structured prompts enabled ChatGPT to engage in in-context learning, with the number of patient examples varying from zero to six. The predictive capabilities of ChatGPT-3.5-turbo and ChatGPT-4 were then compared against a gradient boosting model (GBM) using various performance metrics.</p><p><strong>Results: </strong>From the KSA database, 4,786 patients formed the 7-day mortality prediction dataset, of whom 718 died, and 4,025 patients formed the 30-day dataset, with 1,368 deaths. Age and clinical markers (e.g., Sequential Organ Failure Assessment score and lactic acid levels) showed significant differences between survivors and non-survivors in both datasets. For 7-day mortality predictions, the area under the receiver operating characteristic curve (AUROC) was 0.70-0.83 for GPT-4, 0.51-0.70 for GPT-3.5, and 0.79 for GBM. The AUROC for 30-day mortality was 0.51-0.59 for GPT-4, 0.47-0.57 for GPT-3.5, and 0.76 for GBM. Zero-shot predictions using GPT-4 for mortality from ICU admission to day 30 showed AUROCs from the mid-0.60s to 0.75 for GPT-4 and mainly from 0.47 to 0.63 for GPT-3.5.</p><p><strong>Conclusions: </strong>GPT-4 demonstrated potential in predicting short-term in-hospital mortality, although its performance varied across different evaluation metrics.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":"30 3","pages":"266-276"},"PeriodicalIF":2.1000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11333818/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2024.30.3.266","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/31 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: Sepsis is a leading global cause of mortality, and predicting its outcomes is vital for improving patient care. This study explored the capabilities of ChatGPT, a state-of-the-art natural language processing model, in predicting in-hospital mortality for sepsis patients.
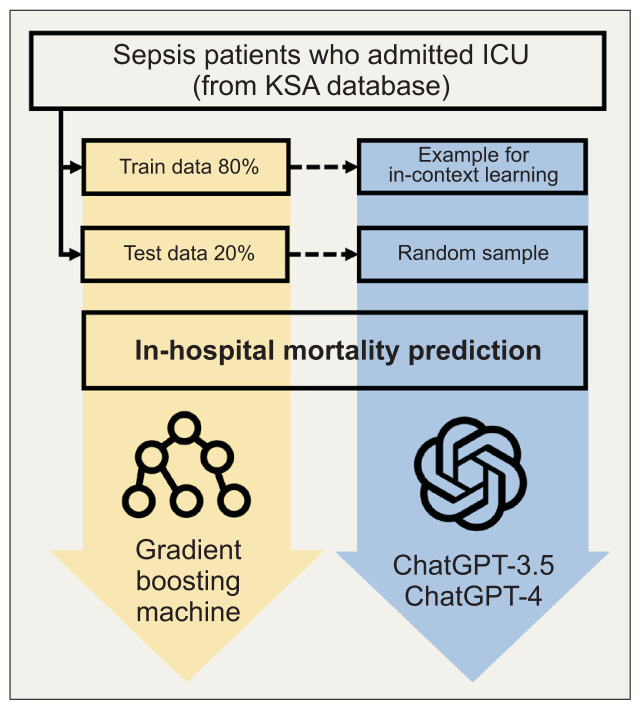
Methods: This study utilized data from the Korean Sepsis Alliance (KSA) database, collected between 2019 and 2021, focusing on adult intensive care unit (ICU) patients and aiming to determine whether ChatGPT could predict all-cause mortality after ICU admission at 7 and 30 days. Structured prompts enabled ChatGPT to engage in in-context learning, with the number of patient examples varying from zero to six. The predictive capabilities of ChatGPT-3.5-turbo and ChatGPT-4 were then compared against a gradient boosting model (GBM) using various performance metrics.
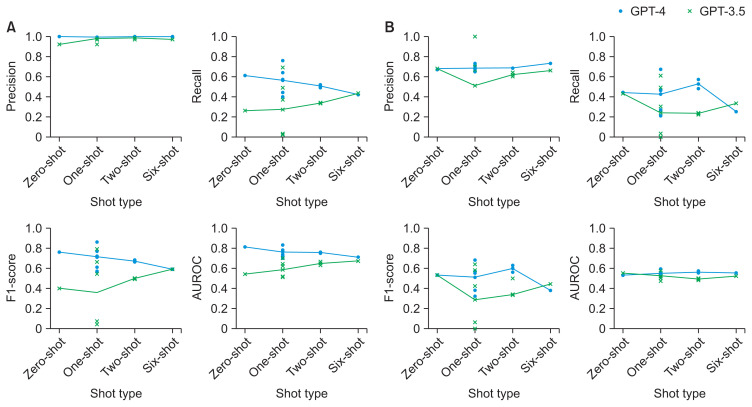
Results: From the KSA database, 4,786 patients formed the 7-day mortality prediction dataset, of whom 718 died, and 4,025 patients formed the 30-day dataset, with 1,368 deaths. Age and clinical markers (e.g., Sequential Organ Failure Assessment score and lactic acid levels) showed significant differences between survivors and non-survivors in both datasets. For 7-day mortality predictions, the area under the receiver operating characteristic curve (AUROC) was 0.70-0.83 for GPT-4, 0.51-0.70 for GPT-3.5, and 0.79 for GBM. The AUROC for 30-day mortality was 0.51-0.59 for GPT-4, 0.47-0.57 for GPT-3.5, and 0.76 for GBM. Zero-shot predictions using GPT-4 for mortality from ICU admission to day 30 showed AUROCs from the mid-0.60s to 0.75 for GPT-4 and mainly from 0.47 to 0.63 for GPT-3.5.
Conclusions: GPT-4 demonstrated potential in predicting short-term in-hospital mortality, although its performance varied across different evaluation metrics.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


