{"title":"OCUCFormer: An Over-Complete Under-Complete Transformer Network for accelerated MRI reconstruction","authors":"Mohammad Al Fahim , Sriprabha Ramanarayanan , G.S. Rahul , Matcha Naga Gayathri , Arunima Sarkar , Keerthi Ram , Mohanasankar Sivaprakasam","doi":"10.1016/j.imavis.2024.105228","DOIUrl":null,"url":null,"abstract":"<div><p>Many deep learning-based architectures have been proposed for accelerated Magnetic Resonance Imaging (MRI) reconstruction. However, existing encoder-decoder-based popular networks have a few shortcomings: (1) They focus on the anatomy structure at the expense of fine details, hindering their performance in generating faithful reconstructions; (2) Lack of long-range dependencies yields sub-optimal recovery of fine structural details. In this work, we propose an Over-Complete Under-Complete Transformer network (OCUCFormer) which focuses on better capturing fine edges and details in the image and can extract the long-range relations between these features for improved single-coil (SC) and multi-coil (MC) MRI reconstruction. Our model computes long-range relations in the highest resolutions using Restormer modules for improved acquisition and restoration of fine anatomical details. Towards learning in the absence of fully sampled ground truth for supervision, we show that our model trained with under-sampled data in a self-supervised fashion shows a superior recovery of fine structures compared to other works. We have extensively evaluated our network for SC and MC MRI reconstruction on brain, cardiac, and knee anatomies for <span><math><mn>4</mn><mo>×</mo></math></span> and <span><math><mn>5</mn><mo>×</mo></math></span> acceleration factors. We report significant improvements over popular deep learning-based methods when trained in supervised and self-supervised modes. We have also performed experiments demonstrating the strengths of extracting fine details and the anatomical structure and computing long-range relations within over-complete representations. Code for our proposed method is available at: <span><span><span>https://github.com/alfahimmohammad/OCUCFormer-main</span></span><svg><path></path></svg></span>.</p></div>","PeriodicalId":50374,"journal":{"name":"Image and Vision Computing","volume":"150 ","pages":"Article 105228"},"PeriodicalIF":4.2000,"publicationDate":"2024-08-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Image and Vision Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0262885624003330","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
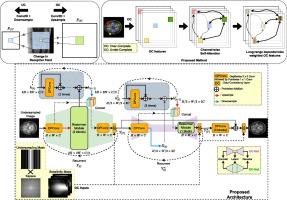
Many deep learning-based architectures have been proposed for accelerated Magnetic Resonance Imaging (MRI) reconstruction. However, existing encoder-decoder-based popular networks have a few shortcomings: (1) They focus on the anatomy structure at the expense of fine details, hindering their performance in generating faithful reconstructions; (2) Lack of long-range dependencies yields sub-optimal recovery of fine structural details. In this work, we propose an Over-Complete Under-Complete Transformer network (OCUCFormer) which focuses on better capturing fine edges and details in the image and can extract the long-range relations between these features for improved single-coil (SC) and multi-coil (MC) MRI reconstruction. Our model computes long-range relations in the highest resolutions using Restormer modules for improved acquisition and restoration of fine anatomical details. Towards learning in the absence of fully sampled ground truth for supervision, we show that our model trained with under-sampled data in a self-supervised fashion shows a superior recovery of fine structures compared to other works. We have extensively evaluated our network for SC and MC MRI reconstruction on brain, cardiac, and knee anatomies for and acceleration factors. We report significant improvements over popular deep learning-based methods when trained in supervised and self-supervised modes. We have also performed experiments demonstrating the strengths of extracting fine details and the anatomical structure and computing long-range relations within over-complete representations. Code for our proposed method is available at: https://github.com/alfahimmohammad/OCUCFormer-main.
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


