Weijian Huang , Cheng Li , Hao Yang , Jiarun Liu , Yong Liang , Hairong Zheng , Shanshan Wang
{"title":"Enhancing the vision–language foundation model with key semantic knowledge-emphasized report refinement","authors":"Weijian Huang , Cheng Li , Hao Yang , Jiarun Liu , Yong Liang , Hairong Zheng , Shanshan Wang","doi":"10.1016/j.media.2024.103299","DOIUrl":null,"url":null,"abstract":"<div><p>Recently, vision–language representation learning has made remarkable advancements in building up medical foundation models, holding immense potential for transforming the landscape of clinical research and medical care. The underlying hypothesis is that the rich knowledge embedded in radiology reports can effectively assist and guide the learning process, reducing the need for additional labels. However, these reports tend to be complex and sometimes even consist of redundant descriptions that make the representation learning too challenging to capture the key semantic information. This paper develops a novel iterative vision–language representation learning framework by proposing a key semantic knowledge-emphasized report refinement method. Particularly, raw radiology reports are refined to highlight the key information according to a constructed clinical dictionary and two model-optimized knowledge-enhancement metrics. The iterative framework is designed to progressively learn, starting from gaining a general understanding of the patient’s condition based on raw reports and gradually refines and extracts critical information essential to the fine-grained analysis tasks. The effectiveness of the proposed framework is validated on various downstream medical image analysis tasks, including disease classification, region-of-interest segmentation, and phrase grounding. Our framework surpasses seven state-of-the-art methods in both fine-tuning and zero-shot settings, demonstrating its encouraging potential for different clinical applications.</p></div>","PeriodicalId":18328,"journal":{"name":"Medical image analysis","volume":"97 ","pages":"Article 103299"},"PeriodicalIF":10.7000,"publicationDate":"2024-08-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical image analysis","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S136184152400224X","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
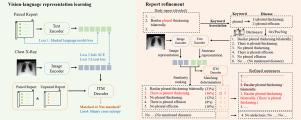
Recently, vision–language representation learning has made remarkable advancements in building up medical foundation models, holding immense potential for transforming the landscape of clinical research and medical care. The underlying hypothesis is that the rich knowledge embedded in radiology reports can effectively assist and guide the learning process, reducing the need for additional labels. However, these reports tend to be complex and sometimes even consist of redundant descriptions that make the representation learning too challenging to capture the key semantic information. This paper develops a novel iterative vision–language representation learning framework by proposing a key semantic knowledge-emphasized report refinement method. Particularly, raw radiology reports are refined to highlight the key information according to a constructed clinical dictionary and two model-optimized knowledge-enhancement metrics. The iterative framework is designed to progressively learn, starting from gaining a general understanding of the patient’s condition based on raw reports and gradually refines and extracts critical information essential to the fine-grained analysis tasks. The effectiveness of the proposed framework is validated on various downstream medical image analysis tasks, including disease classification, region-of-interest segmentation, and phrase grounding. Our framework surpasses seven state-of-the-art methods in both fine-tuning and zero-shot settings, demonstrating its encouraging potential for different clinical applications.
期刊介绍:
Medical Image Analysis serves as a platform for sharing new research findings in the realm of medical and biological image analysis, with a focus on applications of computer vision, virtual reality, and robotics to biomedical imaging challenges. The journal prioritizes the publication of high-quality, original papers contributing to the fundamental science of processing, analyzing, and utilizing medical and biological images. It welcomes approaches utilizing biomedical image datasets across all spatial scales, from molecular/cellular imaging to tissue/organ imaging.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


