Ruiheng Liu , Yu Zhang , Bailong Yang , Qi Shi , Luogeng Tian
{"title":"Robust and resource-efficient table-based fact verification through multi-aspect adversarial contrastive learning","authors":"Ruiheng Liu , Yu Zhang , Bailong Yang , Qi Shi , Luogeng Tian","doi":"10.1016/j.ipm.2024.103853","DOIUrl":null,"url":null,"abstract":"<div><p>Table-based fact verification focuses on determining the truthfulness of statements by cross-referencing data in tables. This task is challenging due to the complex interactions inherent in table structures. To address this challenge, existing methods have devised a range of specialized models. Although these models demonstrate good performance, they still exhibit limited sensitivity to essential variations in information relevant to reasoning within both statements and tables, thus learning spurious patterns and leading to potentially unreliable outcomes. In this work, we propose a novel approach named <strong>M</strong>ulti-Aspect <strong>A</strong>dversarial <strong>Co</strong>ntrastive <strong>L</strong>earning (<span>Macol</span>), aimed at enhancing the accuracy and robustness of table-based fact verification systems under the premise of resource efficiency. Specifically, we first extract pivotal logical reasoning clues to construct positive and adversarial negative instances for contrastive learning. We then propose a new training paradigm that introduces a contrastive learning objective, encouraging the model to recognize noise invariance between original and positive instances while also distinguishing logical differences between original and negative instances. Extensive experimental results on three widely studied datasets TABFACT, INFOTABS and SEM-TAB-FACTS demonstrate that <span>Macol</span> achieves state-of-the-art performance on benchmarks across various backbone architectures, with accuracy improvements reaching up to 5.4%. Furthermore, <span>Macol</span> exhibits significant advantages in robustness and low-data resource scenarios, with improvements of up to 8.2% and 9.1%. It is worth noting that our method achieves comparable or even superior performance while being more resource-efficient compared to approaches that employ specific additional pre-training or utilize large language models (LLMs).</p></div>","PeriodicalId":50365,"journal":{"name":"Information Processing & Management","volume":"61 6","pages":"Article 103853"},"PeriodicalIF":6.9000,"publicationDate":"2024-08-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Information Processing & Management","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0306457324002127","RegionNum":1,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
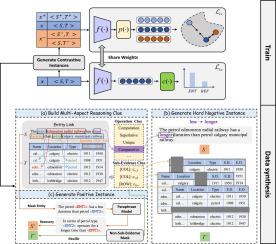
Table-based fact verification focuses on determining the truthfulness of statements by cross-referencing data in tables. This task is challenging due to the complex interactions inherent in table structures. To address this challenge, existing methods have devised a range of specialized models. Although these models demonstrate good performance, they still exhibit limited sensitivity to essential variations in information relevant to reasoning within both statements and tables, thus learning spurious patterns and leading to potentially unreliable outcomes. In this work, we propose a novel approach named Multi-Aspect Adversarial Contrastive Learning (Macol), aimed at enhancing the accuracy and robustness of table-based fact verification systems under the premise of resource efficiency. Specifically, we first extract pivotal logical reasoning clues to construct positive and adversarial negative instances for contrastive learning. We then propose a new training paradigm that introduces a contrastive learning objective, encouraging the model to recognize noise invariance between original and positive instances while also distinguishing logical differences between original and negative instances. Extensive experimental results on three widely studied datasets TABFACT, INFOTABS and SEM-TAB-FACTS demonstrate that Macol achieves state-of-the-art performance on benchmarks across various backbone architectures, with accuracy improvements reaching up to 5.4%. Furthermore, Macol exhibits significant advantages in robustness and low-data resource scenarios, with improvements of up to 8.2% and 9.1%. It is worth noting that our method achieves comparable or even superior performance while being more resource-efficient compared to approaches that employ specific additional pre-training or utilize large language models (LLMs).
期刊介绍:
Information Processing and Management is dedicated to publishing cutting-edge original research at the convergence of computing and information science. Our scope encompasses theory, methods, and applications across various domains, including advertising, business, health, information science, information technology marketing, and social computing.
We aim to cater to the interests of both primary researchers and practitioners by offering an effective platform for the timely dissemination of advanced and topical issues in this interdisciplinary field. The journal places particular emphasis on original research articles, research survey articles, research method articles, and articles addressing critical applications of research. Join us in advancing knowledge and innovation at the intersection of computing and information science.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


