Anna Weber , Aurélien Pélissier , María Rodríguez Martínez
{"title":"T-cell receptor binding prediction: A machine learning revolution","authors":"Anna Weber , Aurélien Pélissier , María Rodríguez Martínez","doi":"10.1016/j.immuno.2024.100040","DOIUrl":null,"url":null,"abstract":"<div><p>Recent advancements in immune sequencing and experimental techniques are generating extensive T cell receptor (TCR) repertoire data, enabling the development of models to predict TCR binding specificity. Despite the computational challenges posed by the vast diversity of TCRs and epitopes, significant progress has been made. This review explores the evolution of computational models designed for this task, emphasizing machine learning efforts, including early unsupervised clustering approaches, supervised models, and recent applications of Protein Language Models (PLMs), deep learning models pretrained on extensive collections of unlabeled protein sequences that capture crucial biological properties.</p><p>We survey the most prominent models in each category and offer a critical discussion on recurrent challenges, including the lack of generalization to new epitopes, dataset biases, and shortcomings in model validation designs. Focusing on PLMs, we discuss the transformative impact of Transformer-based protein models in bioinformatics, particularly in TCR specificity analysis. We discuss recent studies that exploit PLMs to deliver notably competitive performances in TCR-related tasks, while also examining current limitations and future directions. Lastly, we address the pressing need for improved interpretability in these often opaque models, and examine current efforts to extract biological insights from large black box models.</p></div>","PeriodicalId":73343,"journal":{"name":"Immunoinformatics (Amsterdam, Netherlands)","volume":"15 ","pages":"Article 100040"},"PeriodicalIF":0.0000,"publicationDate":"2024-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667119024000107/pdfft?md5=d53078634a01ebcc5850282ff7db1fa1&pid=1-s2.0-S2667119024000107-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Immunoinformatics (Amsterdam, Netherlands)","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667119024000107","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
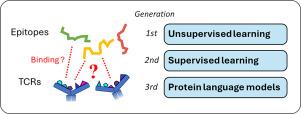
Recent advancements in immune sequencing and experimental techniques are generating extensive T cell receptor (TCR) repertoire data, enabling the development of models to predict TCR binding specificity. Despite the computational challenges posed by the vast diversity of TCRs and epitopes, significant progress has been made. This review explores the evolution of computational models designed for this task, emphasizing machine learning efforts, including early unsupervised clustering approaches, supervised models, and recent applications of Protein Language Models (PLMs), deep learning models pretrained on extensive collections of unlabeled protein sequences that capture crucial biological properties.
We survey the most prominent models in each category and offer a critical discussion on recurrent challenges, including the lack of generalization to new epitopes, dataset biases, and shortcomings in model validation designs. Focusing on PLMs, we discuss the transformative impact of Transformer-based protein models in bioinformatics, particularly in TCR specificity analysis. We discuss recent studies that exploit PLMs to deliver notably competitive performances in TCR-related tasks, while also examining current limitations and future directions. Lastly, we address the pressing need for improved interpretability in these often opaque models, and examine current efforts to extract biological insights from large black box models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


