Stefano Ribes , Eva Nittinger , Christian Tyrchan , Rocío Mercado
{"title":"Modeling PROTAC degradation activity with machine learning","authors":"Stefano Ribes , Eva Nittinger , Christian Tyrchan , Rocío Mercado","doi":"10.1016/j.ailsci.2024.100104","DOIUrl":null,"url":null,"abstract":"<div><p>PROTACs are a promising therapeutic modality that harnesses the cell’s built-in degradation machinery to degrade specific proteins. Despite their potential, developing new PROTACs is challenging and requires significant domain expertise, time, and cost. Meanwhile, machine learning has transformed drug design and development. In this work, we present a strategy for curating open-source PROTAC data and an open-source deep learning tool for predicting the degradation activity of novel PROTAC molecules. The curated dataset incorporates important information such as <span><math><mrow><mi>p</mi><mi>D</mi><msub><mrow><mi>C</mi></mrow><mrow><mn>50</mn></mrow></msub></mrow></math></span>, <span><math><msub><mrow><mi>D</mi></mrow><mrow><mi>m</mi><mi>a</mi><mi>x</mi></mrow></msub></math></span>, E3 ligase type, POI amino acid sequence, and experimental cell type. Our model architecture leverages learned embeddings from pretrained machine learning models, in particular for encoding protein sequences and cell type information. We assessed the quality of the curated data and the generalization ability of our model architecture against new PROTACs and targets via three tailored studies, which we recommend other researchers to use in evaluating their degradation activity models. In each study, three models predict protein degradation in a majority vote setting, reaching a top test accuracy of 82.6% and 0.848 ROC AUC, and a test accuracy of 61% and 0.615 ROC AUC when generalizing to novel protein targets. Our results are not only comparable to state-of-the-art models for protein degradation prediction, but also part of an open-source implementation which is easily reproducible and less computationally complex than existing approaches.</p></div>","PeriodicalId":72304,"journal":{"name":"Artificial intelligence in the life sciences","volume":"6 ","pages":"Article 100104"},"PeriodicalIF":0.0000,"publicationDate":"2024-07-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667318524000114/pdfft?md5=fbcd6191bbd4f65eeacdd8602953af66&pid=1-s2.0-S2667318524000114-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Artificial intelligence in the life sciences","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667318524000114","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
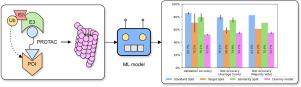
PROTACs are a promising therapeutic modality that harnesses the cell’s built-in degradation machinery to degrade specific proteins. Despite their potential, developing new PROTACs is challenging and requires significant domain expertise, time, and cost. Meanwhile, machine learning has transformed drug design and development. In this work, we present a strategy for curating open-source PROTAC data and an open-source deep learning tool for predicting the degradation activity of novel PROTAC molecules. The curated dataset incorporates important information such as , , E3 ligase type, POI amino acid sequence, and experimental cell type. Our model architecture leverages learned embeddings from pretrained machine learning models, in particular for encoding protein sequences and cell type information. We assessed the quality of the curated data and the generalization ability of our model architecture against new PROTACs and targets via three tailored studies, which we recommend other researchers to use in evaluating their degradation activity models. In each study, three models predict protein degradation in a majority vote setting, reaching a top test accuracy of 82.6% and 0.848 ROC AUC, and a test accuracy of 61% and 0.615 ROC AUC when generalizing to novel protein targets. Our results are not only comparable to state-of-the-art models for protein degradation prediction, but also part of an open-source implementation which is easily reproducible and less computationally complex than existing approaches.
Artificial intelligence in the life sciencesPharmacology, Biochemistry, Genetics and Molecular Biology (General), Computer Science Applications, Health Informatics, Drug Discovery, Veterinary Science and Veterinary Medicine (General)

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


