Hao Liu, Berkay Yucel, Baskar Ganapathysubramanian, Surya R. Kalidindi, Daniel Wheeler and Olga Wodo
{"title":"Active learning for regression of structure–property mapping: the importance of sampling and representation†","authors":"Hao Liu, Berkay Yucel, Baskar Ganapathysubramanian, Surya R. Kalidindi, Daniel Wheeler and Olga Wodo","doi":"10.1039/D4DD00073K","DOIUrl":null,"url":null,"abstract":"<p >Data-driven approaches now allow for systematic mappings from materials microstructures to materials properties. In particular, diverse data-driven approaches are available to establish mappings using varied microstructure representations, each posing different demands on the resources required to calibrate machine learning models. In this work, using active learning regression and iteratively increasing the data pool, three questions are explored: (a) what is the minimal subset of data required to train a predictive structure–property model with sufficient accuracy? (b) Is this minimal subset highly dependent on the sampling strategy managing the datapool? And (c) what is the cost associated with the model calibration? Using case studies with different types of microstructure (composite <em>vs.</em> spinodal), dimensionality (two- and three-dimensional), and properties (elastic and electronic), we explore these questions using two separate microstructure representations: graph-based descriptors derived from a graph representation of the microstructure and two-point correlation functions. This work demonstrates that as few as 5% of evaluations are required to calibrate robust data-driven structure–property maps when selections are made from a library of diverse microstructures. The findings show that both representations (graph-based descriptors and two-point correlation functions) can be effective with only a small quantity of property evaluations when combined with different active learning strategies. However, the dimensionality of the latent space differs substantially depending on the microstructure representation and active learning strategy.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 10","pages":" 1997-2009"},"PeriodicalIF":6.2000,"publicationDate":"2024-08-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/dd/d4dd00073k?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/dd/d4dd00073k","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
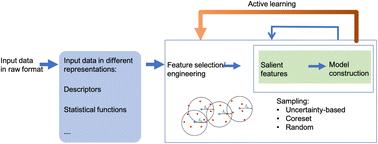
Data-driven approaches now allow for systematic mappings from materials microstructures to materials properties. In particular, diverse data-driven approaches are available to establish mappings using varied microstructure representations, each posing different demands on the resources required to calibrate machine learning models. In this work, using active learning regression and iteratively increasing the data pool, three questions are explored: (a) what is the minimal subset of data required to train a predictive structure–property model with sufficient accuracy? (b) Is this minimal subset highly dependent on the sampling strategy managing the datapool? And (c) what is the cost associated with the model calibration? Using case studies with different types of microstructure (composite vs. spinodal), dimensionality (two- and three-dimensional), and properties (elastic and electronic), we explore these questions using two separate microstructure representations: graph-based descriptors derived from a graph representation of the microstructure and two-point correlation functions. This work demonstrates that as few as 5% of evaluations are required to calibrate robust data-driven structure–property maps when selections are made from a library of diverse microstructures. The findings show that both representations (graph-based descriptors and two-point correlation functions) can be effective with only a small quantity of property evaluations when combined with different active learning strategies. However, the dimensionality of the latent space differs substantially depending on the microstructure representation and active learning strategy.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


