Changhong Shi, Weirong Liu, Jiahao Meng, Xiongfei Jia, Jie Liu
{"title":"Self-prior guided generative adversarial network for image inpainting","authors":"Changhong Shi, Weirong Liu, Jiahao Meng, Xiongfei Jia, Jie Liu","doi":"10.1007/s00371-024-03578-x","DOIUrl":null,"url":null,"abstract":"<p>Great progress has been made in image inpainting tasks with the emergence of convolutional neural networks, because of their superior translation invariance and powerful texture modeling capacity. However, current solutions generally do not perform well in reconstructing high-quality results. To address this issues, a self-prior guided generative adversarial network (SG-GAN) model is proposed. SG-GAN integrates the learning paradigms of cross-attention and convolution to the generator. It is able to learn the cross-mapping between input and target dataset effectively. Then, a high receptive field subnet is constructed to increase the receptive field. Finally, a high receptive field feature-matching loss is proposed to further ensure the structure sharpness of generated images. Experiments on datasets including natural scene images (Places2), facial images (CelebA-HQ), structured wall images (Façade), and Dunhuang Mural images show that the proposed method can generate higher quality results with more details than state-of-the-art.</p>","PeriodicalId":501186,"journal":{"name":"The Visual Computer","volume":"46 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-08-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Visual Computer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00371-024-03578-x","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
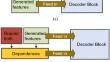
Great progress has been made in image inpainting tasks with the emergence of convolutional neural networks, because of their superior translation invariance and powerful texture modeling capacity. However, current solutions generally do not perform well in reconstructing high-quality results. To address this issues, a self-prior guided generative adversarial network (SG-GAN) model is proposed. SG-GAN integrates the learning paradigms of cross-attention and convolution to the generator. It is able to learn the cross-mapping between input and target dataset effectively. Then, a high receptive field subnet is constructed to increase the receptive field. Finally, a high receptive field feature-matching loss is proposed to further ensure the structure sharpness of generated images. Experiments on datasets including natural scene images (Places2), facial images (CelebA-HQ), structured wall images (Façade), and Dunhuang Mural images show that the proposed method can generate higher quality results with more details than state-of-the-art.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


