Hong Zhao, Wengai Li, Dailin Huang, Jinhai Huang, Lijun Zhang
{"title":"M-GAN: multiattribute learning and multimodal feature fusion-based generative adversarial network for text-to-image synthesis","authors":"Hong Zhao, Wengai Li, Dailin Huang, Jinhai Huang, Lijun Zhang","doi":"10.1007/s00371-024-03585-y","DOIUrl":null,"url":null,"abstract":"<p>Generating high-quality and realistic images based on textual descriptions is a formidable challenge, encompassing three critical aspects: (1) Data imbalance causes difficulties in feature learning when samples from rare categories are underrepresented in existing datasets; (2) multimodal feature fusion is widely used in the past struggles to effectively emphasize key joint features, resulting in weak interactions between different modes; and (3) the entanglement between the generator and discriminator in GANs poses challenges, particularly for the discriminator to effectively fulfill its designated role. To address these issues, this paper proposes a multiattribute learning and multimodal feature fusion-based generative adversarial network (M-GAN). Essentially, this paper contributes: (1) A multiattribute learning approach is introduced to mitigate data imbalance by enhancing heterogeneous vocabulary and category-relevant labels, which facilitates attribute information propagation into images, resulting in images that better meet task requirements; (2) a multimodal feature fusion approach based on gated attention and enhanced attention emphasizes vital information while suppressing non-essential details, enhancing intermodal interaction and improving fusion accuracy through stronger attention to intramodality correlations; and (3) an optimized generative adversarial network structure employs a U-Net discriminator to capture both structural and semantic changes between real and fake images, improving model performance and generating more realistic images by capturing global structure as well as local details. Extensive experiments conducted on the CUB-200 and MS-COCO datasets demonstrate the effectiveness of our M-GAN approach in text-to-image synthesis. The codes will be released at https://github.com/CodeSet1/M-GAN.</p>","PeriodicalId":501186,"journal":{"name":"The Visual Computer","volume":"135 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-08-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Visual Computer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00371-024-03585-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
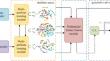
Generating high-quality and realistic images based on textual descriptions is a formidable challenge, encompassing three critical aspects: (1) Data imbalance causes difficulties in feature learning when samples from rare categories are underrepresented in existing datasets; (2) multimodal feature fusion is widely used in the past struggles to effectively emphasize key joint features, resulting in weak interactions between different modes; and (3) the entanglement between the generator and discriminator in GANs poses challenges, particularly for the discriminator to effectively fulfill its designated role. To address these issues, this paper proposes a multiattribute learning and multimodal feature fusion-based generative adversarial network (M-GAN). Essentially, this paper contributes: (1) A multiattribute learning approach is introduced to mitigate data imbalance by enhancing heterogeneous vocabulary and category-relevant labels, which facilitates attribute information propagation into images, resulting in images that better meet task requirements; (2) a multimodal feature fusion approach based on gated attention and enhanced attention emphasizes vital information while suppressing non-essential details, enhancing intermodal interaction and improving fusion accuracy through stronger attention to intramodality correlations; and (3) an optimized generative adversarial network structure employs a U-Net discriminator to capture both structural and semantic changes between real and fake images, improving model performance and generating more realistic images by capturing global structure as well as local details. Extensive experiments conducted on the CUB-200 and MS-COCO datasets demonstrate the effectiveness of our M-GAN approach in text-to-image synthesis. The codes will be released at https://github.com/CodeSet1/M-GAN.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


