M Luke Marinovich, William Lotter, Andrew Waddell, Nehmat Houssami
{"title":"Simulated arbitration of discordance between radiologists and artificial intelligence interpretation of breast cancer screening mammograms.","authors":"M Luke Marinovich, William Lotter, Andrew Waddell, Nehmat Houssami","doi":"10.1177/09691413241262960","DOIUrl":null,"url":null,"abstract":"<p><p>Artificial intelligence (AI) algorithms have been retrospectively evaluated as replacement for one radiologist in screening mammography double-reading; however, methods for resolving discordance between radiologists and AI in the absence of 'real-world' arbitration may underestimate cancer detection rate (CDR) and recall. In 108,970 consecutive screens from a population screening program (BreastScreen WA, Western Australia), 20,120 were radiologist/AI discordant without real-world arbitration. Recall probabilities were randomly assigned for these screens in 1000 simulations. Recall thresholds for screen-detected and interval cancers (sensitivity) and no cancer (false-positive proportion, FPP) were varied to calculate mean CDR and recall rate for the entire cohort. Assuming 100% sensitivity, the maximum CDR was 7.30 per 1000 screens. To achieve >95% probability that the mean CDR exceeded the screening program CDR (6.97 per 1000), interval cancer sensitivities ≥63% (at 100% screen-detected sensitivity) and ≥91% (at 80% screen-detected sensitivity) were required. Mean recall rate was relatively constant across sensitivity assumptions, but varied by FPP. FPP > 6.5% resulted in recall rates that exceeded the program estimate (3.38%). CDR improvements depend on a majority of interval cancers being detected in radiologist/AI discordant screens. Such improvements are likely to increase recall, requiring careful monitoring where AI is deployed for screen-reading.</p>","PeriodicalId":51089,"journal":{"name":"Journal of Medical Screening","volume":" ","pages":"48-52"},"PeriodicalIF":2.3000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11869508/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Medical Screening","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1177/09691413241262960","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/11 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH","Score":null,"Total":0}
引用次数: 0
Abstract
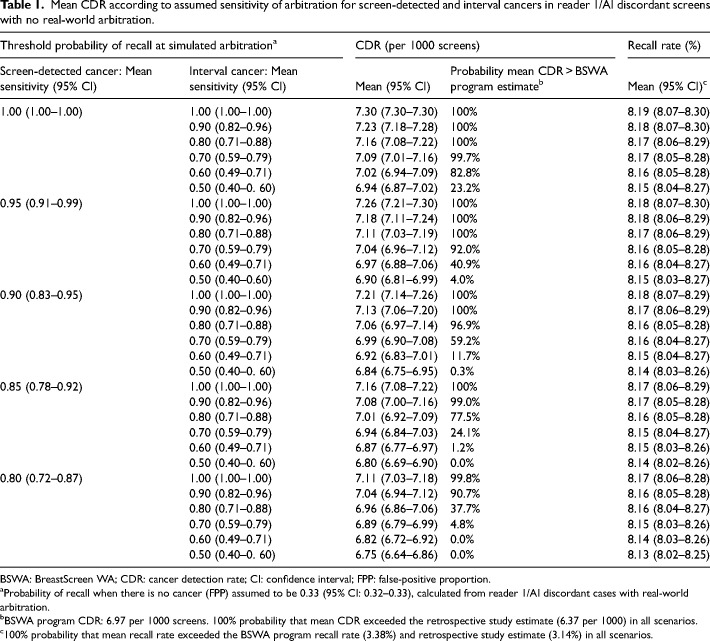
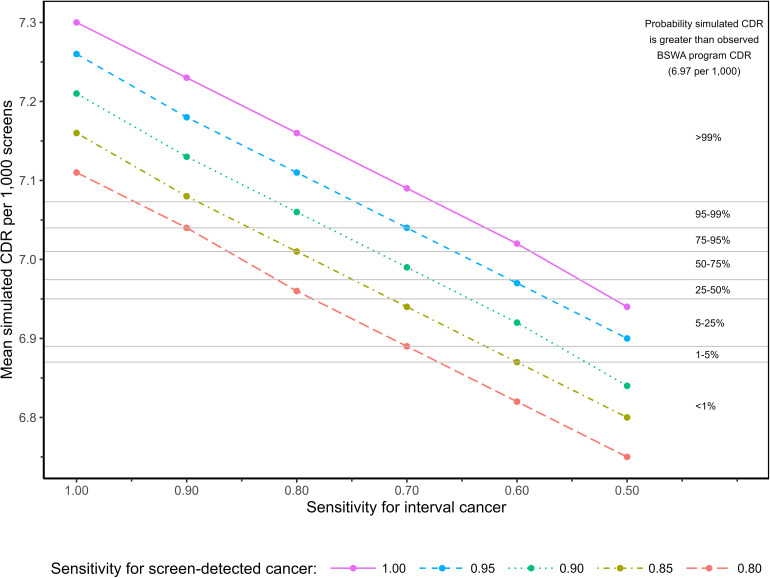
Artificial intelligence (AI) algorithms have been retrospectively evaluated as replacement for one radiologist in screening mammography double-reading; however, methods for resolving discordance between radiologists and AI in the absence of 'real-world' arbitration may underestimate cancer detection rate (CDR) and recall. In 108,970 consecutive screens from a population screening program (BreastScreen WA, Western Australia), 20,120 were radiologist/AI discordant without real-world arbitration. Recall probabilities were randomly assigned for these screens in 1000 simulations. Recall thresholds for screen-detected and interval cancers (sensitivity) and no cancer (false-positive proportion, FPP) were varied to calculate mean CDR and recall rate for the entire cohort. Assuming 100% sensitivity, the maximum CDR was 7.30 per 1000 screens. To achieve >95% probability that the mean CDR exceeded the screening program CDR (6.97 per 1000), interval cancer sensitivities ≥63% (at 100% screen-detected sensitivity) and ≥91% (at 80% screen-detected sensitivity) were required. Mean recall rate was relatively constant across sensitivity assumptions, but varied by FPP. FPP > 6.5% resulted in recall rates that exceeded the program estimate (3.38%). CDR improvements depend on a majority of interval cancers being detected in radiologist/AI discordant screens. Such improvements are likely to increase recall, requiring careful monitoring where AI is deployed for screen-reading.
期刊介绍:
Journal of Medical Screening, a fully peer reviewed journal, is concerned with all aspects of medical screening, particularly the publication of research that advances screening theory and practice. The journal aims to increase awareness of the principles of screening (quantitative and statistical aspects), screening techniques and procedures and methodologies from all specialties. An essential subscription for physicians, clinicians and academics with an interest in screening, epidemiology and public health.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


