Structured stochastic curve fitting without gradient calculation
Journal of Computational Mathematics and Data Science
Pub Date : 2024-07-26
DOI:10.1016/j.jcmds.2024.100097
引用次数: 0
Abstract
Optimization of parameters and hyperparameters is a general process for any data analysis. Because not all models are mathematically well-behaved, stochastic optimization can be useful in many analyses by randomly choosing parameters in each optimization iteration. Many such algorithms have been reported and applied in chemistry data analysis, but the one reported here is interesting to check out, where a naïve algorithm searches each parameter sequentially and randomly in its bounds. Then it picks the best for the next iteration. Thus, one can ignore irrational solution of the model itself or its gradient in parameter space and continue the optimization.
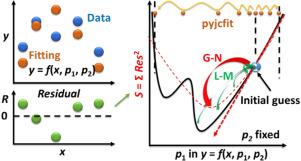
无需梯度计算的结构化随机曲线拟合
参数和超参数的优化是任何数据分析的一般过程。由于并非所有模型都具有良好的数学特性,随机优化可以在每次优化迭代中随机选择参数,从而在许多分析中发挥作用。许多此类算法已被报道并应用于化学数据分析中,但本文报道的算法值得一探究竟。在该算法中,一个天真的算法在其边界内按顺序随机搜索每个参数。然后在下一次迭代中选出最佳方案。因此,我们可以忽略模型本身的不合理解或其在参数空间的梯度,继续进行优化。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


