{"title":"SAM-guided contrast based self-training for source-free cross-domain semantic segmentation","authors":"Qinghua Ren, Ke Hou, Yongzhao Zhan, Chen Wang","doi":"10.1007/s00530-024-01426-5","DOIUrl":null,"url":null,"abstract":"<p>Traditional domain adaptive semantic segmentation methods typically assume access to source domain data during training, a paradigm known as source-access domain adaptation for semantic segmentation (SASS). To address data privacy concerns in real-world applications, source-free domain adaptation for semantic segmentation (SFSS) has recently been studied, eliminating the need for direct access to source data. Most SFSS methods primarily utilize pseudo-labels to regularize the model in either the label space or the feature space. Inspired by the segment anything model (SAM), we propose SAM-guided contrast based pseudo-label learning for SFSS in this work. Unlike previous methods that heavily rely on noisy pseudo-labels, we leverage the class-agnostic segmentation masks generated by SAM as prior knowledge to construct positive and negative sample pairs. This approach allows us to directly shape the feature space using contrastive learning. This design ensures the reliable construction of contrastive samples and exploits both intra-class and intra-instance diversity. Our framework is built upon a vanilla teacher–student network architecture for online pseudo-label learning. Consequently, the SFSS model can be jointly regularized in both the feature and label spaces in an end-to-end manner. Extensive experiments demonstrate that our method achieves competitive performance in two challenging SFSS tasks.</p>","PeriodicalId":51138,"journal":{"name":"Multimedia Systems","volume":"71 1","pages":""},"PeriodicalIF":3.5000,"publicationDate":"2024-07-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00530-024-01426-5","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
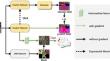
Traditional domain adaptive semantic segmentation methods typically assume access to source domain data during training, a paradigm known as source-access domain adaptation for semantic segmentation (SASS). To address data privacy concerns in real-world applications, source-free domain adaptation for semantic segmentation (SFSS) has recently been studied, eliminating the need for direct access to source data. Most SFSS methods primarily utilize pseudo-labels to regularize the model in either the label space or the feature space. Inspired by the segment anything model (SAM), we propose SAM-guided contrast based pseudo-label learning for SFSS in this work. Unlike previous methods that heavily rely on noisy pseudo-labels, we leverage the class-agnostic segmentation masks generated by SAM as prior knowledge to construct positive and negative sample pairs. This approach allows us to directly shape the feature space using contrastive learning. This design ensures the reliable construction of contrastive samples and exploits both intra-class and intra-instance diversity. Our framework is built upon a vanilla teacher–student network architecture for online pseudo-label learning. Consequently, the SFSS model can be jointly regularized in both the feature and label spaces in an end-to-end manner. Extensive experiments demonstrate that our method achieves competitive performance in two challenging SFSS tasks.
期刊介绍:
This journal details innovative research ideas, emerging technologies, state-of-the-art methods and tools in all aspects of multimedia computing, communication, storage, and applications. It features theoretical, experimental, and survey articles.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


