{"title":"FuseNet: a multi-modal feature fusion network for 3D shape classification","authors":"Xin Zhao, Yinhuang Chen, Chengzhuan Yang, Lincong Fang","doi":"10.1007/s00371-024-03581-2","DOIUrl":null,"url":null,"abstract":"<p>Recently, the primary focus of research in 3D shape classification has been on point cloud and multi-view methods. However, the multi-view approaches inevitably lose the structural information of 3D shapes due to the camera angle limitation. The point cloud methods use a neural network to maximize the pooling of all points to obtain a global feature, resulting in the loss of local detailed information. The disadvantages of multi-view and point cloud methods affect the performance of 3D shape classification. This paper proposes a novel FuseNet model, which integrates multi-view and point cloud information and significantly improves the accuracy of 3D model classification. First, we propose a multi-view and point cloud part to obtain the raw features of different convolution layers of multi-view and point clouds. Second, we adopt a multi-view pooling method for feature fusion of multiple views to integrate features of different convolution layers more effectively, and we propose an attention-based multi-view and point cloud fusion block for integrating features of point cloud and multiple views. Finally, we extensively tested our method on three benchmark datasets: the ModelNet10, ModelNet40, and ShapeNet Core55. Our method’s experimental results demonstrate superior or comparable classification performance to previously established state-of-the-art techniques for 3D shape classification.</p>","PeriodicalId":501186,"journal":{"name":"The Visual Computer","volume":"39 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-07-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Visual Computer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00371-024-03581-2","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
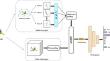
Recently, the primary focus of research in 3D shape classification has been on point cloud and multi-view methods. However, the multi-view approaches inevitably lose the structural information of 3D shapes due to the camera angle limitation. The point cloud methods use a neural network to maximize the pooling of all points to obtain a global feature, resulting in the loss of local detailed information. The disadvantages of multi-view and point cloud methods affect the performance of 3D shape classification. This paper proposes a novel FuseNet model, which integrates multi-view and point cloud information and significantly improves the accuracy of 3D model classification. First, we propose a multi-view and point cloud part to obtain the raw features of different convolution layers of multi-view and point clouds. Second, we adopt a multi-view pooling method for feature fusion of multiple views to integrate features of different convolution layers more effectively, and we propose an attention-based multi-view and point cloud fusion block for integrating features of point cloud and multiple views. Finally, we extensively tested our method on three benchmark datasets: the ModelNet10, ModelNet40, and ShapeNet Core55. Our method’s experimental results demonstrate superior or comparable classification performance to previously established state-of-the-art techniques for 3D shape classification.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


