{"title":"Localization of try block and generation of catch block to handle exception using an improved LSTM","authors":"Preetesh Purohit, Anuradha Purohit, Vrinda Tokekar","doi":"10.1007/s10586-024-04633-x","DOIUrl":null,"url":null,"abstract":"<p>Several contemporary programming languages, including Java, have exception management as a crucial built-in feature. By employing try-catch blocks, it enables developers to handle unusual or unexpected conditions that might arise at runtime beforehand. If exception management is neglected or applied improperly, it may result in serious incidents like equipment failure. Exception handling mechanisms are difficult to implement and time expensive with the preceding methodologies. This research introduces an efficient Long Short Term Memory (LSTM) technique for handling the exceptions automatically, which can identify the locations of the try blocks and automatically create the catch blocks. Bulky java code is collected from GitHub and splitted into several different fragments. For localization of the try block, Bidirectional LSTM (BiLSTM) is used initially as a token level encoder and then as a statement-level encoder. Then, the Support Vector Machine (SVM) is used to predict the try block present in the given source code. For generating a catch block, BiLSTM is initially used as an encoder, and LSTM is used as a decoder. Then, SVM is used here to predict the noisy tokens. The loss functions of this encoder-decoder model have been trained to be as small as possible. The trained model then uses the black widow method to forecast the following tokens one by one and then generates the entire catch block. The proposed work reaches 85% accuracy for try block localization and 50% accuracy for catch block generation. An improved LSTM with an attention mechanism method produces an optimal solution compared to the existing techniques. Thus the proposed method is the best choice for handling the exceptions.</p>","PeriodicalId":501576,"journal":{"name":"Cluster Computing","volume":"82 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-07-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cluster Computing","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10586-024-04633-x","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
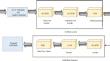
Several contemporary programming languages, including Java, have exception management as a crucial built-in feature. By employing try-catch blocks, it enables developers to handle unusual or unexpected conditions that might arise at runtime beforehand. If exception management is neglected or applied improperly, it may result in serious incidents like equipment failure. Exception handling mechanisms are difficult to implement and time expensive with the preceding methodologies. This research introduces an efficient Long Short Term Memory (LSTM) technique for handling the exceptions automatically, which can identify the locations of the try blocks and automatically create the catch blocks. Bulky java code is collected from GitHub and splitted into several different fragments. For localization of the try block, Bidirectional LSTM (BiLSTM) is used initially as a token level encoder and then as a statement-level encoder. Then, the Support Vector Machine (SVM) is used to predict the try block present in the given source code. For generating a catch block, BiLSTM is initially used as an encoder, and LSTM is used as a decoder. Then, SVM is used here to predict the noisy tokens. The loss functions of this encoder-decoder model have been trained to be as small as possible. The trained model then uses the black widow method to forecast the following tokens one by one and then generates the entire catch block. The proposed work reaches 85% accuracy for try block localization and 50% accuracy for catch block generation. An improved LSTM with an attention mechanism method produces an optimal solution compared to the existing techniques. Thus the proposed method is the best choice for handling the exceptions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


