Miao Chu , Giovanni Luigi De Maria , Ruobing Dai , Stefano Benenati , Wei Yu , Jiaxin Zhong , Rafail Kotronias , Jason Walsh , Stefano Andreaggi , Vittorio Zuccarelli , Jason Chai , Oxford Acute Myocardial Infarction (OxAMI) Study investigators , Keith Channon , Adrian Banning , Shengxian Tu
{"title":"DCCAT: Dual-Coordinate Cross-Attention Transformer for thrombus segmentation on coronary OCT","authors":"Miao Chu , Giovanni Luigi De Maria , Ruobing Dai , Stefano Benenati , Wei Yu , Jiaxin Zhong , Rafail Kotronias , Jason Walsh , Stefano Andreaggi , Vittorio Zuccarelli , Jason Chai , Oxford Acute Myocardial Infarction (OxAMI) Study investigators , Keith Channon , Adrian Banning , Shengxian Tu","doi":"10.1016/j.media.2024.103265","DOIUrl":null,"url":null,"abstract":"<div><p>Acute coronary syndromes (ACS) are one of the leading causes of mortality worldwide, with atherosclerotic plaque rupture and subsequent thrombus formation as the main underlying substrate. Thrombus burden evaluation is important for tailoring treatment therapy and predicting prognosis. Coronary optical coherence tomography (OCT) enables in-vivo visualization of thrombus that cannot otherwise be achieved by other image modalities. However, automatic quantification of thrombus on OCT has not been implemented. The main challenges are due to the variation in location, size and irregularities of thrombus in addition to the small data set. In this paper, we propose a novel dual-coordinate cross-attention transformer network, termed DCCAT, to overcome the above challenges and achieve the first automatic segmentation of thrombus on OCT. Imaging features from both Cartesian and polar coordinates are encoded and fused based on long-range correspondence via multi-head cross-attention mechanism. The dual-coordinate cross-attention block is hierarchically stacked amid convolutional layers at multiple levels, allowing comprehensive feature enhancement. The model was developed based on 5,649 OCT frames from 339 patients and tested using independent external OCT data from 548 frames of 52 patients. DCCAT achieved Dice similarity score (DSC) of 0.706 in segmenting thrombus, which is significantly higher than the CNN-based (0.656) and Transformer-based (0.584) models. We prove that the additional input of polar image not only leverages discriminative features from another coordinate but also improves model robustness for geometrical transformation.Experiment results show that DCCAT achieves competitive performance with only 10% of the total data, highlighting its data efficiency. The proposed dual-coordinate cross-attention design can be easily integrated into other developed Transformer models to boost performance.</p></div>","PeriodicalId":18328,"journal":{"name":"Medical image analysis","volume":"97 ","pages":"Article 103265"},"PeriodicalIF":11.8000,"publicationDate":"2024-07-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical image analysis","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1361841524001907","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
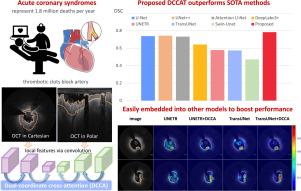
Acute coronary syndromes (ACS) are one of the leading causes of mortality worldwide, with atherosclerotic plaque rupture and subsequent thrombus formation as the main underlying substrate. Thrombus burden evaluation is important for tailoring treatment therapy and predicting prognosis. Coronary optical coherence tomography (OCT) enables in-vivo visualization of thrombus that cannot otherwise be achieved by other image modalities. However, automatic quantification of thrombus on OCT has not been implemented. The main challenges are due to the variation in location, size and irregularities of thrombus in addition to the small data set. In this paper, we propose a novel dual-coordinate cross-attention transformer network, termed DCCAT, to overcome the above challenges and achieve the first automatic segmentation of thrombus on OCT. Imaging features from both Cartesian and polar coordinates are encoded and fused based on long-range correspondence via multi-head cross-attention mechanism. The dual-coordinate cross-attention block is hierarchically stacked amid convolutional layers at multiple levels, allowing comprehensive feature enhancement. The model was developed based on 5,649 OCT frames from 339 patients and tested using independent external OCT data from 548 frames of 52 patients. DCCAT achieved Dice similarity score (DSC) of 0.706 in segmenting thrombus, which is significantly higher than the CNN-based (0.656) and Transformer-based (0.584) models. We prove that the additional input of polar image not only leverages discriminative features from another coordinate but also improves model robustness for geometrical transformation.Experiment results show that DCCAT achieves competitive performance with only 10% of the total data, highlighting its data efficiency. The proposed dual-coordinate cross-attention design can be easily integrated into other developed Transformer models to boost performance.
期刊介绍:
Medical Image Analysis serves as a platform for sharing new research findings in the realm of medical and biological image analysis, with a focus on applications of computer vision, virtual reality, and robotics to biomedical imaging challenges. The journal prioritizes the publication of high-quality, original papers contributing to the fundamental science of processing, analyzing, and utilizing medical and biological images. It welcomes approaches utilizing biomedical image datasets across all spatial scales, from molecular/cellular imaging to tissue/organ imaging.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


