Ayush Kumar Shah, Bryan Amador, Abhisek Dey, Ming Creekmore, Blake Ocampo, Scott Denmark, Richard Zanibbi
{"title":"ChemScraper: leveraging PDF graphics instructions for molecular diagram parsing","authors":"Ayush Kumar Shah, Bryan Amador, Abhisek Dey, Ming Creekmore, Blake Ocampo, Scott Denmark, Richard Zanibbi","doi":"10.1007/s10032-024-00486-7","DOIUrl":null,"url":null,"abstract":"<p>Most molecular diagram parsers recover chemical structure from raster images (e.g., PNGs). However, many PDFs include commands giving explicit locations and shapes for characters, lines, and polygons. We present a new parser that uses these born-digital PDF primitives as input. The parsing model is fast and accurate, and does not require GPUs, Optical Character Recognition (OCR), or vectorization. We use the parser to annotate raster images and then train a new multi-task neural network for recognizing molecules in raster images. We evaluate our parsers using SMILES and standard benchmarks, along with a novel evaluation protocol comparing molecular graphs directly that supports automatic error compilation and reveals errors missed by SMILES-based evaluation. On the synthetic USPTO benchmark, our born-digital parser obtains a recognition rate of 98.4% (1% higher than previous models) and our relatively simple neural parser for raster images obtains a rate of 85% using less training data than existing neural approaches (thousands vs. millions of molecules).</p>","PeriodicalId":50277,"journal":{"name":"International Journal on Document Analysis and Recognition","volume":"5 1","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2024-07-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal on Document Analysis and Recognition","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10032-024-00486-7","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
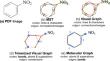
Most molecular diagram parsers recover chemical structure from raster images (e.g., PNGs). However, many PDFs include commands giving explicit locations and shapes for characters, lines, and polygons. We present a new parser that uses these born-digital PDF primitives as input. The parsing model is fast and accurate, and does not require GPUs, Optical Character Recognition (OCR), or vectorization. We use the parser to annotate raster images and then train a new multi-task neural network for recognizing molecules in raster images. We evaluate our parsers using SMILES and standard benchmarks, along with a novel evaluation protocol comparing molecular graphs directly that supports automatic error compilation and reveals errors missed by SMILES-based evaluation. On the synthetic USPTO benchmark, our born-digital parser obtains a recognition rate of 98.4% (1% higher than previous models) and our relatively simple neural parser for raster images obtains a rate of 85% using less training data than existing neural approaches (thousands vs. millions of molecules).
期刊介绍:
The large number of existing documents and the production of a multitude of new ones every year raise important issues in efficient handling, retrieval and storage of these documents and the information which they contain. This has led to the emergence of new research domains dealing with the recognition by computers of the constituent elements of documents - including characters, symbols, text, lines, graphics, images, handwriting, signatures, etc. In addition, these new domains deal with automatic analyses of the overall physical and logical structures of documents, with the ultimate objective of a high-level understanding of their semantic content. We have also seen renewed interest in optical character recognition (OCR) and handwriting recognition during the last decade. Document analysis and recognition are obviously the next stage.
Automatic, intelligent processing of documents is at the intersections of many fields of research, especially of computer vision, image analysis, pattern recognition and artificial intelligence, as well as studies on reading, handwriting and linguistics. Although quality document related publications continue to appear in journals dedicated to these domains, the community will benefit from having this journal as a focal point for archival literature dedicated to document analysis and recognition.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


