Swarnalata Rath, Nilima R. Das, Binod Kumar Pattanayak
{"title":"Stacked BI-LSTM and E-Optimized CNN-A Hybrid Deep Learning Model for Stock Price Prediction","authors":"Swarnalata Rath, Nilima R. Das, Binod Kumar Pattanayak","doi":"10.3103/S1060992X24700024","DOIUrl":null,"url":null,"abstract":"<p>Univariate stocks and multivariate equities are more common due to partnerships. Accurate future stock predictions benefit investors and stakeholders. The study has limitations, but hybrid architectures can outperform single deep learning approach (DL) in price prediction. This study presents a hybrid attention-based optimal DL model that leverages multiple neural networks to enhance stock price prediction accuracy. The model uses strategic optimization of individual model components, extracting crucial insights from stock price time series data. The process involves initial pre-processing, wavelet transform denoising, and min-max normalization, followed by data division into training and test sets. The proposed model integrates stacked Bi-directional Long Short Term Memory (Bi-LSTM), an attention module, and an Equilibrium optimized 1D Convolutional Neural Network (CNN). Stacked Bi-LSTM networks shoot enriched temporal features, while the attention mechanism reduces historical data loss and highlights significant information. A dropout layer with tailored dropout rates is introduced to address overfitting. The Conv1D layer within the 1D CNN detects abrupt data changes using residual features from the dropout layer. The model incorporates Equilibrium Optimization (EO) for training the CNN, allowing the algorithm to select optimal weights based on mean square error. Model efficiency is evaluated through diverse metrics, including Mean Absolute Error (MAE), Mean Square Error (MSE), Root Mean Square Error (RMSE), and R-squared (R2), to confirm the model’s predictive performance.</p>","PeriodicalId":721,"journal":{"name":"Optical Memory and Neural Networks","volume":"33 2","pages":"102 - 120"},"PeriodicalIF":1.0000,"publicationDate":"2024-07-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Optical Memory and Neural Networks","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.3103/S1060992X24700024","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"OPTICS","Score":null,"Total":0}
引用次数: 0
Abstract
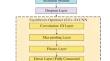
Univariate stocks and multivariate equities are more common due to partnerships. Accurate future stock predictions benefit investors and stakeholders. The study has limitations, but hybrid architectures can outperform single deep learning approach (DL) in price prediction. This study presents a hybrid attention-based optimal DL model that leverages multiple neural networks to enhance stock price prediction accuracy. The model uses strategic optimization of individual model components, extracting crucial insights from stock price time series data. The process involves initial pre-processing, wavelet transform denoising, and min-max normalization, followed by data division into training and test sets. The proposed model integrates stacked Bi-directional Long Short Term Memory (Bi-LSTM), an attention module, and an Equilibrium optimized 1D Convolutional Neural Network (CNN). Stacked Bi-LSTM networks shoot enriched temporal features, while the attention mechanism reduces historical data loss and highlights significant information. A dropout layer with tailored dropout rates is introduced to address overfitting. The Conv1D layer within the 1D CNN detects abrupt data changes using residual features from the dropout layer. The model incorporates Equilibrium Optimization (EO) for training the CNN, allowing the algorithm to select optimal weights based on mean square error. Model efficiency is evaluated through diverse metrics, including Mean Absolute Error (MAE), Mean Square Error (MSE), Root Mean Square Error (RMSE), and R-squared (R2), to confirm the model’s predictive performance.
期刊介绍:
The journal covers a wide range of issues in information optics such as optical memory, mechanisms for optical data recording and processing, photosensitive materials, optical, optoelectronic and holographic nanostructures, and many other related topics. Papers on memory systems using holographic and biological structures and concepts of brain operation are also included. The journal pays particular attention to research in the field of neural net systems that may lead to a new generation of computional technologies by endowing them with intelligence.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


