{"title":"DCSG: data complement pseudo-label refinement and self-guided pre-training for unsupervised person re-identification","authors":"Qing Han, Jiongjin Chen, Weidong Min, Jiahao Li, Lixin Zhan, Longfei Li","doi":"10.1007/s00371-024-03542-9","DOIUrl":null,"url":null,"abstract":"<p>Existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo-labels that are generally noisy, and initializing the model with ImageNet pre-training weights introduces a large domain gap that severely impacts the model’s performance. To address the aforementioned issues, we propose the data complement pseudo-label refinement and self-guided pre-training framework, referred to as DCSG. Firstly, our method utilizes image information from multiple augmentation views to complement the source image data, resulting in aggregated information. We employ this aggregated information to design a correlation score that serves as a reliability evaluation for the source features and cluster centroids. By optimizing the pseudo-labels for each sample, we enhance their robustness. Secondly, we propose a pre-training strategy that leverages the potential information within the training process. This strategy involves mining classes with high similarity in the training set to guide model training and facilitate smooth pre-training. Consequently, the model acquires preliminary capabilities to distinguish pedestrian-related features at an early stage of training, thereby reducing the impact of domain gaps arising from ImageNet pre-training weights. Our method demonstrates superior performance on multiple person Re-ID datasets, validating the effectiveness of our proposed approach. Notably, it achieves an mAP metric of 84.3% on the Market1501 dataset, representing a 2.8% improvement compared to the state-of-the-art method. The code is available at https://github.com/duolaJohn/DCSG.git.</p>","PeriodicalId":501186,"journal":{"name":"The Visual Computer","volume":"22-23 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The Visual Computer","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00371-024-03542-9","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
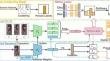
Existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo-labels that are generally noisy, and initializing the model with ImageNet pre-training weights introduces a large domain gap that severely impacts the model’s performance. To address the aforementioned issues, we propose the data complement pseudo-label refinement and self-guided pre-training framework, referred to as DCSG. Firstly, our method utilizes image information from multiple augmentation views to complement the source image data, resulting in aggregated information. We employ this aggregated information to design a correlation score that serves as a reliability evaluation for the source features and cluster centroids. By optimizing the pseudo-labels for each sample, we enhance their robustness. Secondly, we propose a pre-training strategy that leverages the potential information within the training process. This strategy involves mining classes with high similarity in the training set to guide model training and facilitate smooth pre-training. Consequently, the model acquires preliminary capabilities to distinguish pedestrian-related features at an early stage of training, thereby reducing the impact of domain gaps arising from ImageNet pre-training weights. Our method demonstrates superior performance on multiple person Re-ID datasets, validating the effectiveness of our proposed approach. Notably, it achieves an mAP metric of 84.3% on the Market1501 dataset, representing a 2.8% improvement compared to the state-of-the-art method. The code is available at https://github.com/duolaJohn/DCSG.git.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


