Systematic analysis of 32,111 AI model cards characterizes documentation practice in AI
IF 18.8
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
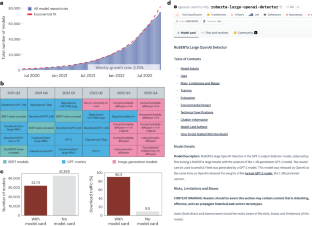
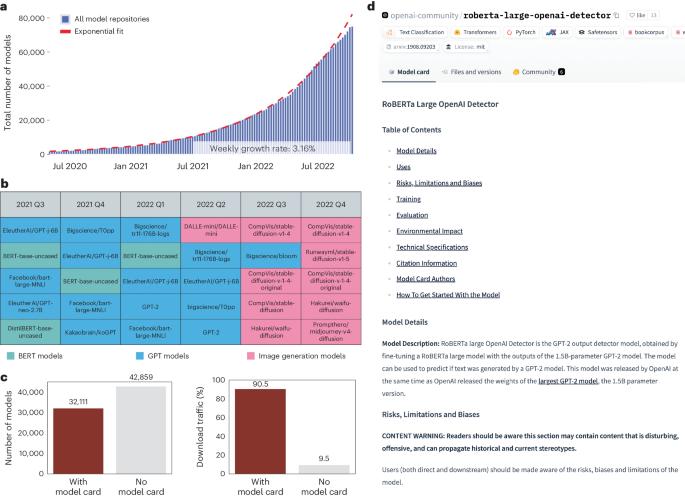
The rapid proliferation of AI models has underscored the importance of thorough documentation, which enables users to understand, trust and effectively use these models in various applications. Although developers are encouraged to produce model cards, it’s not clear how much or what information these cards contain. In this study we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most AI models with a substantial number of downloads provide model cards, although with uneven informativeness. We find that sections addressing environmental impact, limitations and evaluation exhibit the lowest filled-out rates, whereas the training section is the one most consistently filled-out. We analyse the content of each section to characterize practitioners’ priorities. Interestingly, there are considerable discussions of data, sometimes with equal or even greater emphasis than the model itself. Our study provides a systematic assessment of community norms and practices surroinding model documentation through large-scale data science and linguistic analysis. As the number of AI models has rapidly grown, there is an increased focus on improving the documentation through model cards. Liang et al. explore questions around adoption practices and the type of information provided in model cards through a large-scale analysis of 32,111 model card documentation from 74,970 models.
对 32 111 张人工智能模型卡进行系统分析,揭示人工智能文献实践的特点
人工智能模型的迅速扩散凸显了详尽文档的重要性,它能让用户理解、信任并在各种应用中有效地使用这些模型。尽管我们鼓励开发者制作模型卡片,但这些卡片包含多少信息或包含哪些信息却并不清楚。在本研究中,我们对 Hugging Face 上的 32111 份人工智能模型文档进行了全面分析,Hugging Face 是分发和部署人工智能模型的领先平台。我们的调查揭示了模型卡片文档的普遍做法。大多数有大量下载的人工智能模型都提供了模型卡,但信息量参差不齐。我们发现,涉及环境影响、局限性和评估的部分填写率最低,而训练部分则是填写率最高的部分。我们分析了每个部分的内容,以确定实践者的优先事项。有趣的是,我们对数据进行了大量讨论,有时对数据的重视程度甚至超过了模型本身。我们的研究通过大规模的数据科学和语言学分析,系统地评估了模型文档之外的社区规范和实践。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


