{"title":"Using diffusion models to generate synthetic labeled data for medical image segmentation.","authors":"Daniel G Saragih, Atsuhiro Hibi, Pascal N Tyrrell","doi":"10.1007/s11548-024-03213-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Medical image analysis has become a prominent area where machine learning has been applied. However, high-quality, publicly available data are limited either due to patient privacy laws or the time and cost required for experts to annotate images. In this retrospective study, we designed and evaluated a pipeline to generate synthetic labeled polyp images for augmenting medical image segmentation models with the aim of reducing this data scarcity.</p><p><strong>Methods: </strong>We trained diffusion models on the HyperKvasir dataset, comprising 1000 images of polyps in the human GI tract from 2008 to 2016. Qualitative expert review, Fréchet Inception Distance (FID), and Multi-Scale Structural Similarity (MS-SSIM) were tested for evaluation. Additionally, various segmentation models were trained with the generated data and evaluated using Dice score (DS) and Intersection over Union (IoU).</p><p><strong>Results: </strong>Our pipeline produced images more akin to real polyp images based on FID scores. Segmentation model performance also showed improvements over GAN methods when trained entirely, or partially, with synthetic data, despite requiring less compute for training. Moreover, the improvement persists when tested on different datasets, showcasing the transferability of the generated images.</p><p><strong>Conclusions: </strong>The proposed pipeline produced realistic image and mask pairs which could reduce the need for manual data annotation when performing a machine learning task. We support this use case by showing that the methods proposed in this study enhanced segmentation model performance, as measured by Dice and IoU scores, when trained fully or partially on synthetic data.</p>","PeriodicalId":51251,"journal":{"name":"International Journal of Computer Assisted Radiology and Surgery","volume":null,"pages":null},"PeriodicalIF":2.3000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Assisted Radiology and Surgery","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s11548-024-03213-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/20 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"ENGINEERING, BIOMEDICAL","Score":null,"Total":0}
引用次数: 0
Abstract
Purpose: Medical image analysis has become a prominent area where machine learning has been applied. However, high-quality, publicly available data are limited either due to patient privacy laws or the time and cost required for experts to annotate images. In this retrospective study, we designed and evaluated a pipeline to generate synthetic labeled polyp images for augmenting medical image segmentation models with the aim of reducing this data scarcity.
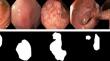
Methods: We trained diffusion models on the HyperKvasir dataset, comprising 1000 images of polyps in the human GI tract from 2008 to 2016. Qualitative expert review, Fréchet Inception Distance (FID), and Multi-Scale Structural Similarity (MS-SSIM) were tested for evaluation. Additionally, various segmentation models were trained with the generated data and evaluated using Dice score (DS) and Intersection over Union (IoU).
Results: Our pipeline produced images more akin to real polyp images based on FID scores. Segmentation model performance also showed improvements over GAN methods when trained entirely, or partially, with synthetic data, despite requiring less compute for training. Moreover, the improvement persists when tested on different datasets, showcasing the transferability of the generated images.
Conclusions: The proposed pipeline produced realistic image and mask pairs which could reduce the need for manual data annotation when performing a machine learning task. We support this use case by showing that the methods proposed in this study enhanced segmentation model performance, as measured by Dice and IoU scores, when trained fully or partially on synthetic data.
期刊介绍:
The International Journal for Computer Assisted Radiology and Surgery (IJCARS) is a peer-reviewed journal that provides a platform for closing the gap between medical and technical disciplines, and encourages interdisciplinary research and development activities in an international environment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


