Tim Dong, Shubhra Sinha, Ben Zhai, Daniel Fudulu, Jeremy Chan, Pradeep Narayan, Andy Judge, Massimo Caputo, Arnaldo Dimagli, Umberto Benedetto, Gianni D Angelini
{"title":"Performance Drift in Machine Learning Models for Cardiac Surgery Risk Prediction: Retrospective Analysis.","authors":"Tim Dong, Shubhra Sinha, Ben Zhai, Daniel Fudulu, Jeremy Chan, Pradeep Narayan, Andy Judge, Massimo Caputo, Arnaldo Dimagli, Umberto Benedetto, Gianni D Angelini","doi":"10.2196/45973","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The Society of Thoracic Surgeons and European System for Cardiac Operative Risk Evaluation (EuroSCORE) II risk scores are the most commonly used risk prediction models for in-hospital mortality after adult cardiac surgery. However, they are prone to miscalibration over time and poor generalization across data sets; thus, their use remains controversial. Despite increased interest, a gap in understanding the effect of data set drift on the performance of machine learning (ML) over time remains a barrier to its wider use in clinical practice. Data set drift occurs when an ML system underperforms because of a mismatch between the data it was developed from and the data on which it is deployed.</p><p><strong>Objective: </strong>In this study, we analyzed the extent of performance drift using models built on a large UK cardiac surgery database. The objectives were to (1) rank and assess the extent of performance drift in cardiac surgery risk ML models over time and (2) investigate any potential influence of data set drift and variable importance drift on performance drift.</p><p><strong>Methods: </strong>We conducted a retrospective analysis of prospectively, routinely gathered data on adult patients undergoing cardiac surgery in the United Kingdom between 2012 and 2019. We temporally split the data 70:30 into a training and validation set and a holdout set. Five novel ML mortality prediction models were developed and assessed, along with EuroSCORE II, for relationships between and within variable importance drift, performance drift, and actual data set drift. Performance was assessed using a consensus metric.</p><p><strong>Results: </strong>A total of 227,087 adults underwent cardiac surgery during the study period, with a mortality rate of 2.76% (n=6258). There was strong evidence of a decrease in overall performance across all models (P<.0001). Extreme gradient boosting (clinical effectiveness metric [CEM] 0.728, 95% CI 0.728-0.729) and random forest (CEM 0.727, 95% CI 0.727-0.728) were the overall best-performing models, both temporally and nontemporally. EuroSCORE II performed the worst across all comparisons. Sharp changes in variable importance and data set drift from October to December 2017, from June to July 2018, and from December 2018 to February 2019 mirrored the effects of performance decrease across models.</p><p><strong>Conclusions: </strong>All models show a decrease in at least 3 of the 5 individual metrics. CEM and variable importance drift detection demonstrate the limitation of logistic regression methods used for cardiac surgery risk prediction and the effects of data set drift. Future work will be required to determine the interplay between ML models and whether ensemble models could improve on their respective performance advantages.</p>","PeriodicalId":73558,"journal":{"name":"JMIRx med","volume":"5 ","pages":"e45973"},"PeriodicalIF":0.0000,"publicationDate":"2024-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11217160/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIRx med","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/45973","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The Society of Thoracic Surgeons and European System for Cardiac Operative Risk Evaluation (EuroSCORE) II risk scores are the most commonly used risk prediction models for in-hospital mortality after adult cardiac surgery. However, they are prone to miscalibration over time and poor generalization across data sets; thus, their use remains controversial. Despite increased interest, a gap in understanding the effect of data set drift on the performance of machine learning (ML) over time remains a barrier to its wider use in clinical practice. Data set drift occurs when an ML system underperforms because of a mismatch between the data it was developed from and the data on which it is deployed.
Objective: In this study, we analyzed the extent of performance drift using models built on a large UK cardiac surgery database. The objectives were to (1) rank and assess the extent of performance drift in cardiac surgery risk ML models over time and (2) investigate any potential influence of data set drift and variable importance drift on performance drift.
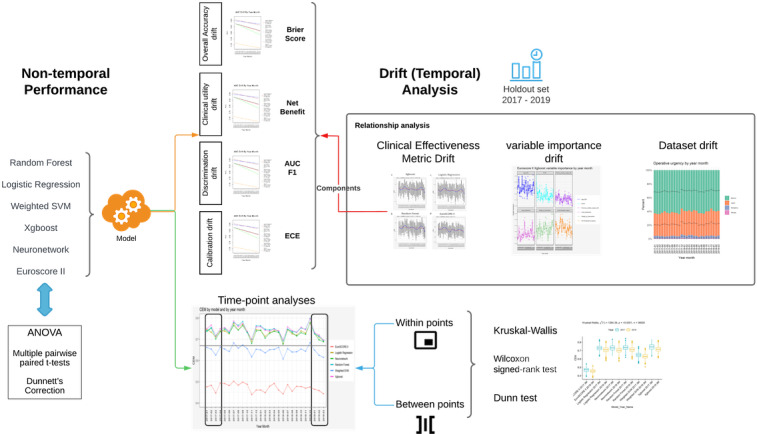
Methods: We conducted a retrospective analysis of prospectively, routinely gathered data on adult patients undergoing cardiac surgery in the United Kingdom between 2012 and 2019. We temporally split the data 70:30 into a training and validation set and a holdout set. Five novel ML mortality prediction models were developed and assessed, along with EuroSCORE II, for relationships between and within variable importance drift, performance drift, and actual data set drift. Performance was assessed using a consensus metric.
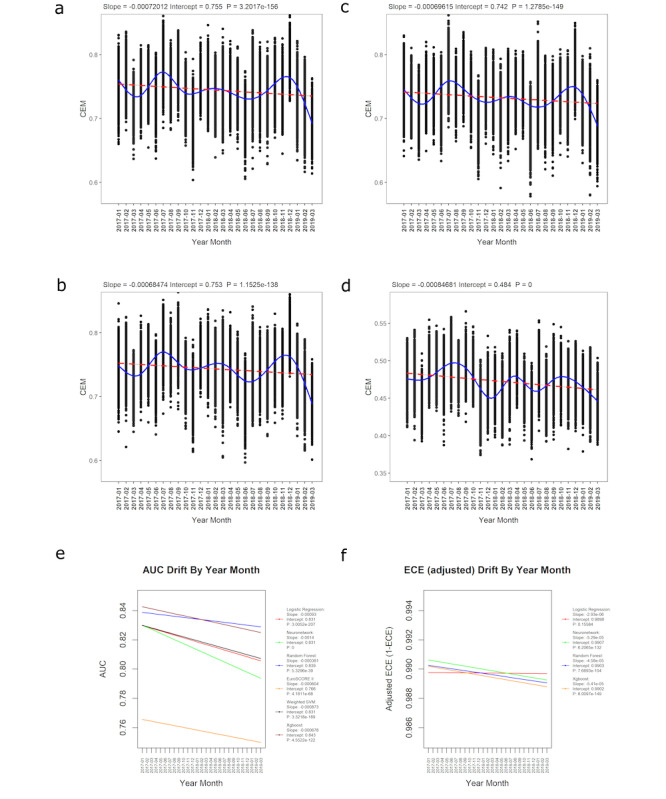
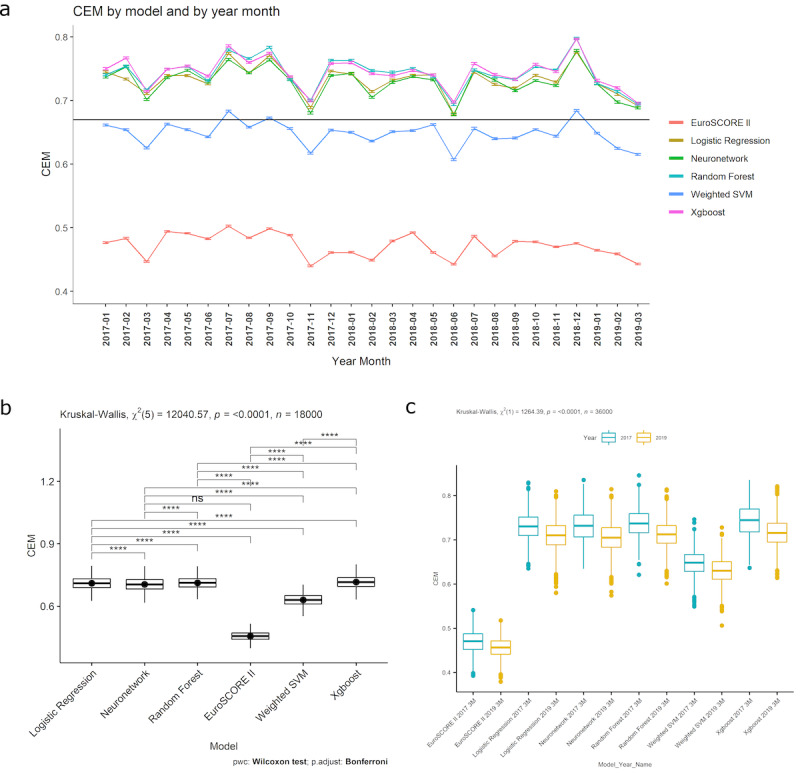
Results: A total of 227,087 adults underwent cardiac surgery during the study period, with a mortality rate of 2.76% (n=6258). There was strong evidence of a decrease in overall performance across all models (P<.0001). Extreme gradient boosting (clinical effectiveness metric [CEM] 0.728, 95% CI 0.728-0.729) and random forest (CEM 0.727, 95% CI 0.727-0.728) were the overall best-performing models, both temporally and nontemporally. EuroSCORE II performed the worst across all comparisons. Sharp changes in variable importance and data set drift from October to December 2017, from June to July 2018, and from December 2018 to February 2019 mirrored the effects of performance decrease across models.
Conclusions: All models show a decrease in at least 3 of the 5 individual metrics. CEM and variable importance drift detection demonstrate the limitation of logistic regression methods used for cardiac surgery risk prediction and the effects of data set drift. Future work will be required to determine the interplay between ML models and whether ensemble models could improve on their respective performance advantages.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


