M. Battogtokh, Y. Xing, C. Davidescu, A. Abdul-Rahman, M. Luck, R. Borgo
{"title":"Visual Analytics for Fine-grained Text Classification Models and Datasets","authors":"M. Battogtokh, Y. Xing, C. Davidescu, A. Abdul-Rahman, M. Luck, R. Borgo","doi":"10.1111/cgf.15098","DOIUrl":null,"url":null,"abstract":"<div>\n \n <p>In natural language processing (NLP), text classification tasks are increasingly fine-grained, as datasets are fragmented into a larger number of classes that are more difficult to differentiate from one another. As a consequence, the semantic structures of datasets have become more complex, and model decisions more difficult to explain. Existing tools, suited for coarse-grained classification, falter under these additional challenges. In response to this gap, we worked closely with NLP domain experts in an iterative design-and-evaluation process to characterize and tackle the growing requirements in their workflow of developing fine-grained text classification models. The result of this collaboration is the development of SemLa, a novel Visual Analytics system tailored for 1) dissecting complex semantic structures in a dataset when it is spatialized in model embedding space, and 2) visualizing fine-grained nuances in the meaning of text samples to faithfully explain model reasoning. This paper details the iterative design study and the resulting innovations featured in SemLa. The final design allows contrastive analysis at different levels by unearthing lexical and conceptual patterns including biases and artifacts in data. Expert feedback on our final design and case studies confirm that SemLa is a useful tool for supporting model validation and debugging as well as data annotation.</p>\n </div>","PeriodicalId":10687,"journal":{"name":"Computer Graphics Forum","volume":null,"pages":null},"PeriodicalIF":2.7000,"publicationDate":"2024-06-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/cgf.15098","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Graphics Forum","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/cgf.15098","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
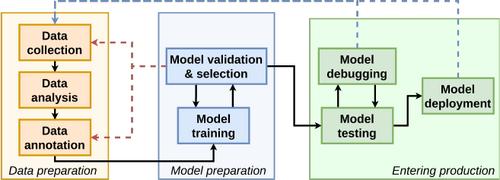
In natural language processing (NLP), text classification tasks are increasingly fine-grained, as datasets are fragmented into a larger number of classes that are more difficult to differentiate from one another. As a consequence, the semantic structures of datasets have become more complex, and model decisions more difficult to explain. Existing tools, suited for coarse-grained classification, falter under these additional challenges. In response to this gap, we worked closely with NLP domain experts in an iterative design-and-evaluation process to characterize and tackle the growing requirements in their workflow of developing fine-grained text classification models. The result of this collaboration is the development of SemLa, a novel Visual Analytics system tailored for 1) dissecting complex semantic structures in a dataset when it is spatialized in model embedding space, and 2) visualizing fine-grained nuances in the meaning of text samples to faithfully explain model reasoning. This paper details the iterative design study and the resulting innovations featured in SemLa. The final design allows contrastive analysis at different levels by unearthing lexical and conceptual patterns including biases and artifacts in data. Expert feedback on our final design and case studies confirm that SemLa is a useful tool for supporting model validation and debugging as well as data annotation.
期刊介绍:
Computer Graphics Forum is the official journal of Eurographics, published in cooperation with Wiley-Blackwell, and is a unique, international source of information for computer graphics professionals interested in graphics developments worldwide. It is now one of the leading journals for researchers, developers and users of computer graphics in both commercial and academic environments. The journal reports on the latest developments in the field throughout the world and covers all aspects of the theory, practice and application of computer graphics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


