Christos Kaikousidis, Robert R. Bies, Aristides Dokoumetzidis
{"title":"Simulating realistic patient profiles from pharmacokinetic models by a machine learning postprocessing correction of residual variability","authors":"Christos Kaikousidis, Robert R. Bies, Aristides Dokoumetzidis","doi":"10.1002/psp4.13182","DOIUrl":null,"url":null,"abstract":"<p>We address the problem of model misspecification in population pharmacokinetics (PopPK), by modeling residual unexplained variability (RUV) by machine learning (ML) methods in a postprocessing step after conventional model building. The practical purpose of the method is the generation of realistic virtual patient profiles and the quantification of the extent of model misspecification, by introducing an appropriate metric, to be used as an additional diagnostic of model quality. The proposed methodology consists of the following steps: After developing a PopPK model, the individual residual errors <i>IRES = DV–IPRED</i>, are computed, where DV are the observations and IPRED the individual predictions and are modeled by ML to obtain <i>IRES</i><sub><i>ML</i></sub>. Correction of the IPREDs can then be carried out as <i>DV</i><sub><i>ML</i></sub> <i>= IPRED + IRES</i><sub><i>ML</i></sub>. The methodology was tested in a PK study of ropinirole, for which a PopPK model was developed while a second deliberately misspecified model was also considered. Various supervised ML algorithms were tested, among which Random Forest gave the best results. The ML model was able to correct individual predictions as inspected in diagnostic plots and most importantly it simulated realistic profiles that resembled the real data and canceled out the artifacts introduced by the elevated RUV, even in the case of the heavily misspecified model. Furthermore, a metric to quantify the extent of model misspecification was introduced based on the <i>R</i><sup>2</sup> between IRES and IRES<sub>ML</sub>, following the rationale that the greater the extent of variability explained by the ML model, the higher the degree of model misspecification present in the original model.</p>","PeriodicalId":10774,"journal":{"name":"CPT: Pharmacometrics & Systems Pharmacology","volume":"13 9","pages":"1476-1487"},"PeriodicalIF":3.1000,"publicationDate":"2024-06-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/psp4.13182","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"CPT: Pharmacometrics & Systems Pharmacology","FirstCategoryId":"3","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/psp4.13182","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PHARMACOLOGY & PHARMACY","Score":null,"Total":0}
引用次数: 0
Abstract
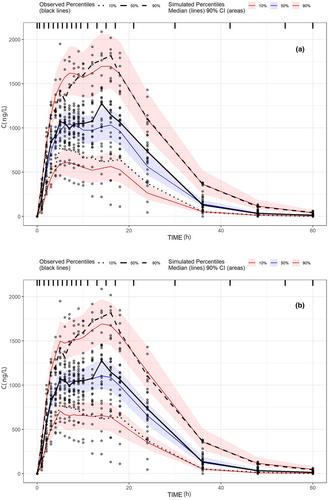
We address the problem of model misspecification in population pharmacokinetics (PopPK), by modeling residual unexplained variability (RUV) by machine learning (ML) methods in a postprocessing step after conventional model building. The practical purpose of the method is the generation of realistic virtual patient profiles and the quantification of the extent of model misspecification, by introducing an appropriate metric, to be used as an additional diagnostic of model quality. The proposed methodology consists of the following steps: After developing a PopPK model, the individual residual errors IRES = DV–IPRED, are computed, where DV are the observations and IPRED the individual predictions and are modeled by ML to obtain IRESML. Correction of the IPREDs can then be carried out as DVML= IPRED + IRESML. The methodology was tested in a PK study of ropinirole, for which a PopPK model was developed while a second deliberately misspecified model was also considered. Various supervised ML algorithms were tested, among which Random Forest gave the best results. The ML model was able to correct individual predictions as inspected in diagnostic plots and most importantly it simulated realistic profiles that resembled the real data and canceled out the artifacts introduced by the elevated RUV, even in the case of the heavily misspecified model. Furthermore, a metric to quantify the extent of model misspecification was introduced based on the R2 between IRES and IRESML, following the rationale that the greater the extent of variability explained by the ML model, the higher the degree of model misspecification present in the original model.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


