{"title":"A unified approach for Parkinson's disease recognition: imbalance mitigation and grid search optimized boosting with LightGBM.","authors":"Bhanja Kishor Swain, Subhashree Mohapatra, Manohar Mishra, Renu Sharma","doi":"10.1007/s11517-024-03139-3","DOIUrl":null,"url":null,"abstract":"<p><p>The work elucidates the importance of accurate Parkinson's disease classification within medical diagnostics and introduces a novel framework for achieving this goal. Specifically, the study focuses on enhancing disease identification accuracy utilizing boosting methods. A standout contribution of this work lies in the utilization of a light gradient boosting machine (LGBM) coupled with hyperparameter tuning through grid search optimization (GSO) on the Parkinson's disease dataset derived from speech recording signals. In addition, the Synthetic Minority Over-sampling Technique (SMOTE) has also been employed as a pre-processing technique to balance the dataset, enhancing the robustness and reliability of the analysis. This approach is a novel addition to the study and underscores its potential to enhance disease identification accuracy. The datasets employed in this work include both gender-specific and combined cases, utilizing several distinctive feature subsets including baseline, Mel-frequency cepstral coefficients (MFCC), time-frequency, wavelet transform (WT), vocal fold, and tunable-Q-factor wavelet transform (TQWT). Comparative analyses against state-of-the-art boosting methods, such as AdaBoost and XG-Boost, reveal the superior performance of our proposed approach across diverse datasets and metrics. Notably, on the male cohort dataset, our method achieves exceptional results, demonstrating an accuracy of 0.98, precision of 1.00, sensitivity of 0.97, F1-Score of 0.98, and specificity of 1.00 when utilizing all features with GSO-LGBM. In comparison to AdaBoost and XGBoost, the proposed framework utilizing LGBM demonstrates superior accuracy, achieving an average improvement of 5% in classification accuracy across all feature subsets and datasets. These findings underscore the potential of the proposed methodology to enhance disease identification accuracy and provide valuable insights for further advancements in medical diagnostics.</p>","PeriodicalId":49840,"journal":{"name":"Medical & Biological Engineering & Computing","volume":null,"pages":null},"PeriodicalIF":2.6000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Medical & Biological Engineering & Computing","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s11517-024-03139-3","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/6/14 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
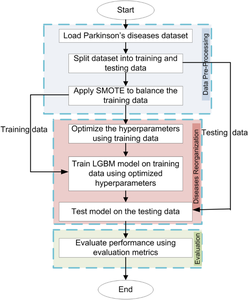
The work elucidates the importance of accurate Parkinson's disease classification within medical diagnostics and introduces a novel framework for achieving this goal. Specifically, the study focuses on enhancing disease identification accuracy utilizing boosting methods. A standout contribution of this work lies in the utilization of a light gradient boosting machine (LGBM) coupled with hyperparameter tuning through grid search optimization (GSO) on the Parkinson's disease dataset derived from speech recording signals. In addition, the Synthetic Minority Over-sampling Technique (SMOTE) has also been employed as a pre-processing technique to balance the dataset, enhancing the robustness and reliability of the analysis. This approach is a novel addition to the study and underscores its potential to enhance disease identification accuracy. The datasets employed in this work include both gender-specific and combined cases, utilizing several distinctive feature subsets including baseline, Mel-frequency cepstral coefficients (MFCC), time-frequency, wavelet transform (WT), vocal fold, and tunable-Q-factor wavelet transform (TQWT). Comparative analyses against state-of-the-art boosting methods, such as AdaBoost and XG-Boost, reveal the superior performance of our proposed approach across diverse datasets and metrics. Notably, on the male cohort dataset, our method achieves exceptional results, demonstrating an accuracy of 0.98, precision of 1.00, sensitivity of 0.97, F1-Score of 0.98, and specificity of 1.00 when utilizing all features with GSO-LGBM. In comparison to AdaBoost and XGBoost, the proposed framework utilizing LGBM demonstrates superior accuracy, achieving an average improvement of 5% in classification accuracy across all feature subsets and datasets. These findings underscore the potential of the proposed methodology to enhance disease identification accuracy and provide valuable insights for further advancements in medical diagnostics.
期刊介绍:
Founded in 1963, Medical & Biological Engineering & Computing (MBEC) continues to serve the biomedical engineering community, covering the entire spectrum of biomedical and clinical engineering. The journal presents exciting and vital experimental and theoretical developments in biomedical science and technology, and reports on advances in computer-based methodologies in these multidisciplinary subjects. The journal also incorporates new and evolving technologies including cellular engineering and molecular imaging.
MBEC publishes original research articles as well as reviews and technical notes. Its Rapid Communications category focuses on material of immediate value to the readership, while the Controversies section provides a forum to exchange views on selected issues, stimulating a vigorous and informed debate in this exciting and high profile field.
MBEC is an official journal of the International Federation of Medical and Biological Engineering (IFMBE).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


