Yongtang Bao, Xiang Liu, Yue Qi, Ruijun Liu, Haojie Li
{"title":"Adaptive information fusion network for multi-modal personality recognition","authors":"Yongtang Bao, Xiang Liu, Yue Qi, Ruijun Liu, Haojie Li","doi":"10.1002/cav.2268","DOIUrl":null,"url":null,"abstract":"<p>Personality recognition is of great significance in deepening the understanding of social relations. While personality recognition methods have made significant strides in recent years, the challenge of heterogeneity between modalities during feature fusion still needs to be solved. This paper introduces an adaptive multi-modal information fusion network (AMIF-Net) capable of concurrently processing video, audio, and text data. First, utilizing the AMIF-Net encoder, we process the extracted audio and video features separately, effectively capturing long-term data relationships. Then, adding adaptive elements in the fusion network can alleviate the problem of heterogeneity between modes. Lastly, we concatenate audio-video and text features into a regression network to obtain Big Five personality trait scores. Furthermore, we introduce a novel loss function to address the problem of training inaccuracies, taking advantage of its unique property of exhibiting a peak at the critical mean. Our tests on the ChaLearn First Impressions V2 multi-modal dataset show partial performance surpassing state-of-the-art networks.</p>","PeriodicalId":50645,"journal":{"name":"Computer Animation and Virtual Worlds","volume":"35 3","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2024-06-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Animation and Virtual Worlds","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cav.2268","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
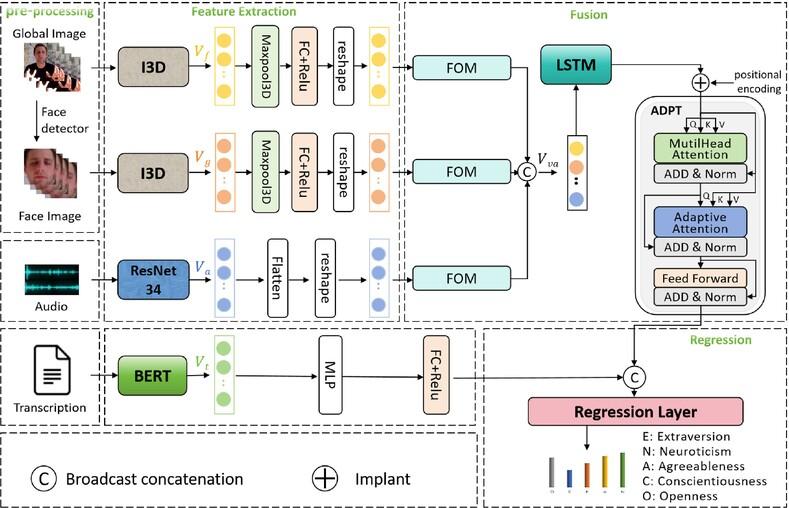
Personality recognition is of great significance in deepening the understanding of social relations. While personality recognition methods have made significant strides in recent years, the challenge of heterogeneity between modalities during feature fusion still needs to be solved. This paper introduces an adaptive multi-modal information fusion network (AMIF-Net) capable of concurrently processing video, audio, and text data. First, utilizing the AMIF-Net encoder, we process the extracted audio and video features separately, effectively capturing long-term data relationships. Then, adding adaptive elements in the fusion network can alleviate the problem of heterogeneity between modes. Lastly, we concatenate audio-video and text features into a regression network to obtain Big Five personality trait scores. Furthermore, we introduce a novel loss function to address the problem of training inaccuracies, taking advantage of its unique property of exhibiting a peak at the critical mean. Our tests on the ChaLearn First Impressions V2 multi-modal dataset show partial performance surpassing state-of-the-art networks.
期刊介绍:
With the advent of very powerful PCs and high-end graphics cards, there has been an incredible development in Virtual Worlds, real-time computer animation and simulation, games. But at the same time, new and cheaper Virtual Reality devices have appeared allowing an interaction with these real-time Virtual Worlds and even with real worlds through Augmented Reality. Three-dimensional characters, especially Virtual Humans are now of an exceptional quality, which allows to use them in the movie industry. But this is only a beginning, as with the development of Artificial Intelligence and Agent technology, these characters will become more and more autonomous and even intelligent. They will inhabit the Virtual Worlds in a Virtual Life together with animals and plants.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


