{"title":"Meta-Meshing and Triangulating Lattice Structures at a Large Scale","authors":"Qiang Zou, Yunzhu Gao, Guoyue Luo, Sifan Chen","doi":"10.1016/j.cad.2024.103732","DOIUrl":null,"url":null,"abstract":"<div><p>Lattice structures have been widely used in applications due to their superior mechanical properties. To fabricate such structures, a geometric processing step called triangulation is often employed to transform them into the STL format before sending them to 3D printers. Because lattice structures tend to have high geometric complexity, this step usually generates a large amount of triangles, a memory and compute-intensive task. This problem manifests itself clearly through large-scale lattice structures that have millions or billions of struts. To address this problem, this paper proposes to transform a lattice structure into an intermediate model called meta-mesh before undergoing real triangulation. Compared to triangular meshes, meta-meshes are very lightweight and much less compute-demanding. The meta-mesh can also work as a base mesh reusable for conveniently and efficiently triangulating lattice structures with arbitrary resolutions. A CPU+GPU asynchronous meta-meshing pipeline has been developed to efficiently generate meta-meshes from lattice structures. It shifts from the thread-centric GPU algorithm design paradigm commonly used in CAD to the recent warp-centric design paradigm to achieve high performance. This is achieved by a new data compression method, a GPU cache-aware data structure, and a workload-balanced scheduling method that can significantly reduce memory divergence and branch divergence. Experimenting with various billion-scale lattice structures, the proposed method is seen to be two orders of magnitude faster than previously achievable.</p></div>","PeriodicalId":50632,"journal":{"name":"Computer-Aided Design","volume":"174 ","pages":"Article 103732"},"PeriodicalIF":3.1000,"publicationDate":"2024-05-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer-Aided Design","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0010448524000599","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
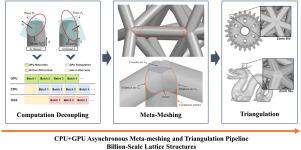
Lattice structures have been widely used in applications due to their superior mechanical properties. To fabricate such structures, a geometric processing step called triangulation is often employed to transform them into the STL format before sending them to 3D printers. Because lattice structures tend to have high geometric complexity, this step usually generates a large amount of triangles, a memory and compute-intensive task. This problem manifests itself clearly through large-scale lattice structures that have millions or billions of struts. To address this problem, this paper proposes to transform a lattice structure into an intermediate model called meta-mesh before undergoing real triangulation. Compared to triangular meshes, meta-meshes are very lightweight and much less compute-demanding. The meta-mesh can also work as a base mesh reusable for conveniently and efficiently triangulating lattice structures with arbitrary resolutions. A CPU+GPU asynchronous meta-meshing pipeline has been developed to efficiently generate meta-meshes from lattice structures. It shifts from the thread-centric GPU algorithm design paradigm commonly used in CAD to the recent warp-centric design paradigm to achieve high performance. This is achieved by a new data compression method, a GPU cache-aware data structure, and a workload-balanced scheduling method that can significantly reduce memory divergence and branch divergence. Experimenting with various billion-scale lattice structures, the proposed method is seen to be two orders of magnitude faster than previously achievable.
期刊介绍:
Computer-Aided Design is a leading international journal that provides academia and industry with key papers on research and developments in the application of computers to design.
Computer-Aided Design invites papers reporting new research, as well as novel or particularly significant applications, within a wide range of topics, spanning all stages of design process from concept creation to manufacture and beyond.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


