Hava K. Blair, Jessica L. Gutknecht, Anna M. Cates, Ann Marcelle Lewandowski, Nicolas Adam Jelinski
{"title":"A data-driven topsoil classification framework to support soil health assessment in Minnesota","authors":"Hava K. Blair, Jessica L. Gutknecht, Anna M. Cates, Ann Marcelle Lewandowski, Nicolas Adam Jelinski","doi":"10.1002/agg2.20523","DOIUrl":null,"url":null,"abstract":"<p>Soil health assessments aim to quantify soil health status using indicators linked to ecosystem services such as yield, nutrient cycling, water cycling, or carbon storage. Many indicators are related to soil biological processes, which can be challenging to interpret because they are sensitive not only to management, but also to nonmanagement variables such as soil inherent properties, topography, and climate. Existing studies address this challenge by grouping similar soils by taxonomy, geography, or a combination of these and other variables for soil health assessment. We investigated whether grouping soils based on multiple quantitative topsoil properties could be an alternative to taxonomic or geographic groups. We used an unsupervised classification algorithm, <i>k</i>-means, to cluster publicly available soil and climate data for Minnesota. Clustering into eight conceptual groups (“clusters”) based on 10 topsoil properties was determined to be the optimal algorithm output. We evaluated the ability of our soil clusters and other grouping methods to explain variance in eight soil health indicators. We found the combination of Major Land Resource Area (MLRA) and soil cluster performed best, explaining as much or more variance than other groupings for five of the eight indicators. The clusters distinguish zones of topsoil variation at the field scale, and MLRAs account for broader scale variation in climate and other landscape factors. The approach we describe is flexible and could be applied at different locations and scales to produce conceptual soil groups and associated maps to support soil health test sampling and interpretation at the field scale.</p>","PeriodicalId":7567,"journal":{"name":"Agrosystems, Geosciences & Environment","volume":"7 2","pages":""},"PeriodicalIF":1.3000,"publicationDate":"2024-05-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/agg2.20523","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Agrosystems, Geosciences & Environment","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/agg2.20523","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"AGRONOMY","Score":null,"Total":0}
引用次数: 0
Abstract
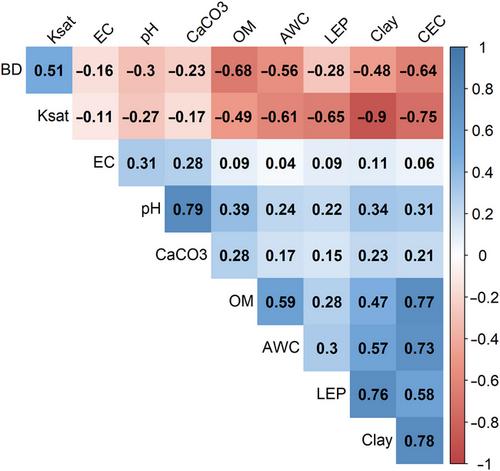
Soil health assessments aim to quantify soil health status using indicators linked to ecosystem services such as yield, nutrient cycling, water cycling, or carbon storage. Many indicators are related to soil biological processes, which can be challenging to interpret because they are sensitive not only to management, but also to nonmanagement variables such as soil inherent properties, topography, and climate. Existing studies address this challenge by grouping similar soils by taxonomy, geography, or a combination of these and other variables for soil health assessment. We investigated whether grouping soils based on multiple quantitative topsoil properties could be an alternative to taxonomic or geographic groups. We used an unsupervised classification algorithm, k-means, to cluster publicly available soil and climate data for Minnesota. Clustering into eight conceptual groups (“clusters”) based on 10 topsoil properties was determined to be the optimal algorithm output. We evaluated the ability of our soil clusters and other grouping methods to explain variance in eight soil health indicators. We found the combination of Major Land Resource Area (MLRA) and soil cluster performed best, explaining as much or more variance than other groupings for five of the eight indicators. The clusters distinguish zones of topsoil variation at the field scale, and MLRAs account for broader scale variation in climate and other landscape factors. The approach we describe is flexible and could be applied at different locations and scales to produce conceptual soil groups and associated maps to support soil health test sampling and interpretation at the field scale.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


