A potential relation trigger method for entity-relation quintuple extraction in text with excessive entities
Abstract
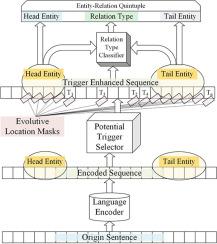
In the task of joint entity and relation extraction, the relationship between two entities is determined by some specific words in their source text. These words are viewed as potential triggers which are the evidence to explain the relationship but not marked clearly. However, the current models cannot make good use of the potential words to optimize components of entities and relations, but can only give separate results. These models aim to identify the type of relation between two entities mentioned in the source text by encoding the text and entities. Although some models can generate the weights for every single word by improving the attention mechanism, the weights will be influenced by the irrelevant words essentially, which is not needed in enhancing the influence of the triggers. We propose a joint entity-relation quintuple extraction framework based on the Potential Relation Trigger (PRT) method to get the highest probability of a word as the prompt in every time step and join the words together as relation hints. In specific, we leverage polarization mechanism in possibility calculation to avoid nondifferentiable points of the functions in our method when choosing. We find that their representation will improve the performance of the relation part with the exact range of the entities. Extensive experiments results demonstrate that the effectiveness of our proposed model achieves state-of-the-art performance on four RE benchmark datasets.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


