Xujie Gong, Ruichao Lei, Ruize Sun, Xue Jiang, Yanjing Su, Yu Yan
{"title":"An ensemble learning strategy for multi-source hydrogen embrittlement data by introducing missing information","authors":"Xujie Gong, Ruichao Lei, Ruize Sun, Xue Jiang, Yanjing Su, Yu Yan","doi":"10.1002/mgea.35","DOIUrl":null,"url":null,"abstract":"<p>Accurately and quickly predicting hydrogen embrittlement performance is critical for the service of metal materials. However, due to multi-source heterogeneity, existing hydrogen embrittlement data are missing, making it impractical to train reliable machine learning models. In this study, we proposed an ensemble learning training strategy for missing data based on the Adaboost algorithm. This method introduced a mask matrix with missing data and enabled each round of training to generate sub-datasets, considering missing value information. The strategy first trained a subset of features based on the existing dataset and a selected method and continuously focused on the combination of features with the highest error for iterative training, where the mask matrix of the missing data was used as the input to fit the weights of each base learner using a neural network. Compared with directly modeling on highly sparse data, the predictive ability of this strategy was significantly improved by approximately 20%. In addition, in the testing of new samples, the predicted mean absolute error of the new model was successfully reduced from 0.2 to 0.09. This strategy offers good adaptability to the hydrogen embrittlement sensitivity of different sizes and can avoid interference from feature importance caused by filling data.</p>","PeriodicalId":100889,"journal":{"name":"Materials Genome Engineering Advances","volume":"2 2","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/mgea.35","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Materials Genome Engineering Advances","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/mgea.35","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
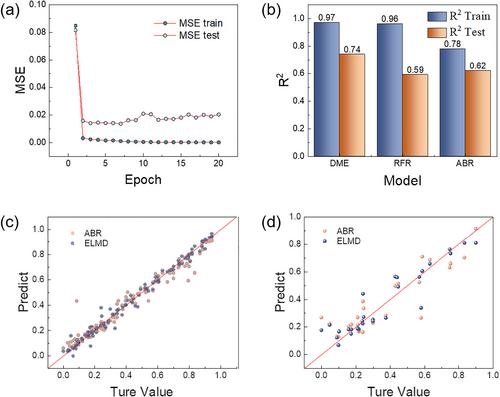
Accurately and quickly predicting hydrogen embrittlement performance is critical for the service of metal materials. However, due to multi-source heterogeneity, existing hydrogen embrittlement data are missing, making it impractical to train reliable machine learning models. In this study, we proposed an ensemble learning training strategy for missing data based on the Adaboost algorithm. This method introduced a mask matrix with missing data and enabled each round of training to generate sub-datasets, considering missing value information. The strategy first trained a subset of features based on the existing dataset and a selected method and continuously focused on the combination of features with the highest error for iterative training, where the mask matrix of the missing data was used as the input to fit the weights of each base learner using a neural network. Compared with directly modeling on highly sparse data, the predictive ability of this strategy was significantly improved by approximately 20%. In addition, in the testing of new samples, the predicted mean absolute error of the new model was successfully reduced from 0.2 to 0.09. This strategy offers good adaptability to the hydrogen embrittlement sensitivity of different sizes and can avoid interference from feature importance caused by filling data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


