The performance of large language models on quantitative and verbal ability tests: Initial evidence and implications for unproctored high-stakes testing
{"title":"The performance of large language models on quantitative and verbal ability tests: Initial evidence and implications for unproctored high-stakes testing","authors":"Louis Hickman, Patrick D. Dunlop, Jasper Leo Wolf","doi":"10.1111/ijsa.12479","DOIUrl":null,"url":null,"abstract":"<p>Unproctored assessments are widely used in pre-employment assessment. However, widely accessible large language models (LLMs) pose challenges for unproctored personnel assessments, given that applicants may use them to artificially inflate their scores beyond their true abilities. This may be particularly concerning in cognitive ability tests, which are widely used and traditionally considered to be less fakeable by humans than personality tests. Thus, this study compares the performance of LLMs on two common types of cognitive tests: quantitative ability (number series completion) and verbal ability (use a passage of text to determine whether a statement is true). The tests investigated are used in real-world, high-stakes selection. We also examine the performance of the LLMs across different test formats (i.e., open-ended vs. multiple choice). Further, we contrast the performance of two LLMs (Generative Pretrained Transformers, GPT-3.5 and GPT-4) across multiple prompt approaches and “temperature” settings (i.e., a parameter that determines the amount of randomness in the model's output). We found that the LLMs performed well on the verbal ability test but extremely poorly on the quantitative ability test, even when accounting for the test format. GPT-4 outperformed GPT-3.5 across both types of tests. Notably, although prompt approaches and temperature settings did affect LLM test performance, those effects were mostly minor relative to differences across tests and language models. We provide recommendations for securing pre-employment testing against LLM influences. Additionally, we call for rigorous research investigating the prevalence of LLM usage in pre-employment testing as well as on how LLM usage affects selection test validity.</p>","PeriodicalId":51465,"journal":{"name":"International Journal of Selection and Assessment","volume":"32 4","pages":"499-511"},"PeriodicalIF":2.4000,"publicationDate":"2024-05-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/ijsa.12479","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Selection and Assessment","FirstCategoryId":"91","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/ijsa.12479","RegionNum":4,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MANAGEMENT","Score":null,"Total":0}
引用次数: 0
Abstract
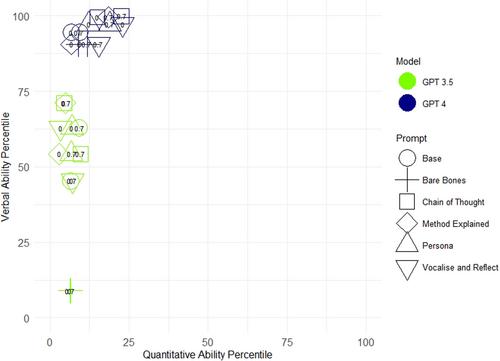
Unproctored assessments are widely used in pre-employment assessment. However, widely accessible large language models (LLMs) pose challenges for unproctored personnel assessments, given that applicants may use them to artificially inflate their scores beyond their true abilities. This may be particularly concerning in cognitive ability tests, which are widely used and traditionally considered to be less fakeable by humans than personality tests. Thus, this study compares the performance of LLMs on two common types of cognitive tests: quantitative ability (number series completion) and verbal ability (use a passage of text to determine whether a statement is true). The tests investigated are used in real-world, high-stakes selection. We also examine the performance of the LLMs across different test formats (i.e., open-ended vs. multiple choice). Further, we contrast the performance of two LLMs (Generative Pretrained Transformers, GPT-3.5 and GPT-4) across multiple prompt approaches and “temperature” settings (i.e., a parameter that determines the amount of randomness in the model's output). We found that the LLMs performed well on the verbal ability test but extremely poorly on the quantitative ability test, even when accounting for the test format. GPT-4 outperformed GPT-3.5 across both types of tests. Notably, although prompt approaches and temperature settings did affect LLM test performance, those effects were mostly minor relative to differences across tests and language models. We provide recommendations for securing pre-employment testing against LLM influences. Additionally, we call for rigorous research investigating the prevalence of LLM usage in pre-employment testing as well as on how LLM usage affects selection test validity.
期刊介绍:
The International Journal of Selection and Assessment publishes original articles related to all aspects of personnel selection, staffing, and assessment in organizations. Using an effective combination of academic research with professional-led best practice, IJSA aims to develop new knowledge and understanding in these important areas of work psychology and contemporary workforce management.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


