Siddhesh Mehta, Rushikesh Karwa, Rahul Chavan, Vaibhav Khatavkar, Amit Joshi
{"title":"Keyphrase extraction using graph-based statistical approach with NLP patterns","authors":"Siddhesh Mehta, Rushikesh Karwa, Rahul Chavan, Vaibhav Khatavkar, Amit Joshi","doi":"10.1007/s12046-024-02494-z","DOIUrl":null,"url":null,"abstract":"<p>Extracting keyphrases plays a vital role in the field of natural language processing, that focuses on recognizing and retrieving significant phrases that summarize the essential information in a document. This research paper introduces a novel approach to extract keyphrases using a statistical approach based on graphs that incorporates degree centrality, TextRank, closeness, and betweenness measures and natural language processing patterns. This approach involves constructing a graph representation of the document and identifying the most important nodes in the graph and leveraging natural language processing patterns to enhance the accuracy and relevance of the extracted keyphrases. The proposed model is examined on a standard dataset for performance evaluation and its outcomes are evaluated by comparing them with the state-of-art methods for extracting keyphrases. The precision, recall, and F-measure achieved by the proposed model are 0.5263, 0.5498, and 0.5323, respectively which shows that proposed model outperforms existing models. The principal novelty of this methodology resides in the utilization of statistical techniques based on graphs and patterns of natural language processing, which enable the detection of the most pertinent nodes and keyphrases of utmost significance. The proposed approach is generalizable to a wide range of domains and text types, making it a promising approach for keyphrase extraction in various applications, including content analysis, document classification, and search engine optimization. In conclusion, the proposed approach offers a robust and scalable solution for identifying keyphrases that capture the essential information of a document. Future research can build upon this approach to improve the efficiency and effectiveness of automated text analysis.</p>","PeriodicalId":21498,"journal":{"name":"Sādhanā","volume":"31 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-05-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Sādhanā","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s12046-024-02494-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
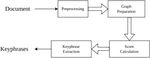
Extracting keyphrases plays a vital role in the field of natural language processing, that focuses on recognizing and retrieving significant phrases that summarize the essential information in a document. This research paper introduces a novel approach to extract keyphrases using a statistical approach based on graphs that incorporates degree centrality, TextRank, closeness, and betweenness measures and natural language processing patterns. This approach involves constructing a graph representation of the document and identifying the most important nodes in the graph and leveraging natural language processing patterns to enhance the accuracy and relevance of the extracted keyphrases. The proposed model is examined on a standard dataset for performance evaluation and its outcomes are evaluated by comparing them with the state-of-art methods for extracting keyphrases. The precision, recall, and F-measure achieved by the proposed model are 0.5263, 0.5498, and 0.5323, respectively which shows that proposed model outperforms existing models. The principal novelty of this methodology resides in the utilization of statistical techniques based on graphs and patterns of natural language processing, which enable the detection of the most pertinent nodes and keyphrases of utmost significance. The proposed approach is generalizable to a wide range of domains and text types, making it a promising approach for keyphrase extraction in various applications, including content analysis, document classification, and search engine optimization. In conclusion, the proposed approach offers a robust and scalable solution for identifying keyphrases that capture the essential information of a document. Future research can build upon this approach to improve the efficiency and effectiveness of automated text analysis.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


