{"title":"Amharic spoken digits recognition using convolutional neural network","authors":"Tewodros Alemu Ayall, Changjun Zhou, Huawen Liu, Getnet Mezgebu Brhanemeskel, Solomon Teferra Abate, Michael Adjeisah","doi":"10.1186/s40537-024-00910-z","DOIUrl":null,"url":null,"abstract":"<p>Spoken digits recognition (SDR) is a type of supervised automatic speech recognition, which is required in various human–machine interaction applications. It is utilized in phone-based services like dialing systems, certain bank operations, airline reservation systems, and price extraction. However, the design of SDR is a challenging task that requires the development of labeled audio data, the proper choice of feature extraction method, and the development of the best performing model. Even if several works have been done for various languages, such as English, Arabic, Urdu, etc., there is no developed Amharic spoken digits dataset (AmSDD) to build Amharic spoken digits recognition (AmSDR) model for the Amharic language, which is the official working language of the government of Ethiopia. Therefore, in this study, we developed a new AmSDD that contains 12,000 utterances of 0 (Zaero) to 9 (zet’enyi) digits which were recorded from 120 volunteer speakers of different age groups, genders, and dialects who repeated each digit ten times. Mel frequency cepstral coefficients (MFCCs) and Mel-Spectrogram feature extraction methods were used to extract trainable features from the speech signal. We conducted different experiments on the development of the AmSDR model using the AmSDD and classical supervised learning algorithms such as Linear Discriminant Analysis (LDA), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Random Forest (RF) as the baseline. To further improve the performance recognition of AmSDR, we propose a three layers Convolutional Neural Network (CNN) architecture with Batch normalization. The results of our experiments show that the proposed CNN model outperforms the baseline algorithms and scores an accuracy of 99% and 98% using MFCCs and Mel-Spectrogram features, respectively.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"21 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-05-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00910-z","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
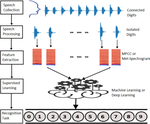
Spoken digits recognition (SDR) is a type of supervised automatic speech recognition, which is required in various human–machine interaction applications. It is utilized in phone-based services like dialing systems, certain bank operations, airline reservation systems, and price extraction. However, the design of SDR is a challenging task that requires the development of labeled audio data, the proper choice of feature extraction method, and the development of the best performing model. Even if several works have been done for various languages, such as English, Arabic, Urdu, etc., there is no developed Amharic spoken digits dataset (AmSDD) to build Amharic spoken digits recognition (AmSDR) model for the Amharic language, which is the official working language of the government of Ethiopia. Therefore, in this study, we developed a new AmSDD that contains 12,000 utterances of 0 (Zaero) to 9 (zet’enyi) digits which were recorded from 120 volunteer speakers of different age groups, genders, and dialects who repeated each digit ten times. Mel frequency cepstral coefficients (MFCCs) and Mel-Spectrogram feature extraction methods were used to extract trainable features from the speech signal. We conducted different experiments on the development of the AmSDR model using the AmSDD and classical supervised learning algorithms such as Linear Discriminant Analysis (LDA), K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Random Forest (RF) as the baseline. To further improve the performance recognition of AmSDR, we propose a three layers Convolutional Neural Network (CNN) architecture with Batch normalization. The results of our experiments show that the proposed CNN model outperforms the baseline algorithms and scores an accuracy of 99% and 98% using MFCCs and Mel-Spectrogram features, respectively.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


