Clayton W. Kosonocky, Claus O. Wilke, Edward M. Marcotte and Andrew D. Ellington
{"title":"Mining patents with large language models elucidates the chemical function landscape†","authors":"Clayton W. Kosonocky, Claus O. Wilke, Edward M. Marcotte and Andrew D. Ellington","doi":"10.1039/D4DD00011K","DOIUrl":null,"url":null,"abstract":"<p >The fundamental goal of small molecule discovery is to generate chemicals with target functionality. While this often proceeds through structure-based methods, we set out to investigate the practicality of methods that leverage the extensive corpus of chemical literature. We hypothesize that a sufficiently large text-derived chemical function dataset would mirror the actual landscape of chemical functionality. Such a landscape would implicitly capture complex physical and biological interactions given that chemical function arises from both a molecule's structure and its interacting partners. To evaluate this hypothesis, we built a Chemical Function (CheF) dataset of patent-derived functional labels. This dataset, comprising 631 K molecule–function pairs, was created using an LLM- and embedding-based method to obtain 1.5 K unique functional labels for approximately 100 K randomly selected molecules from their corresponding 188 K unique patents. We carry out a series of analyses demonstrating that the CheF dataset contains a semantically coherent textual representation of the functional landscape congruent with chemical structural relationships, thus approximating the actual chemical function landscape. We then demonstrate through several examples that this text-based functional landscape can be leveraged to identify drugs with target functionality using a model able to predict functional profiles from structure alone. We believe that functional label-guided molecular discovery may serve as an alternative approach to traditional structure-based methods in the pursuit of designing novel functional molecules.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 6","pages":" 1150-1159"},"PeriodicalIF":6.2000,"publicationDate":"2024-05-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/dd/d4dd00011k?page=search","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/dd/d4dd00011k","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
引用次数: 0
Abstract
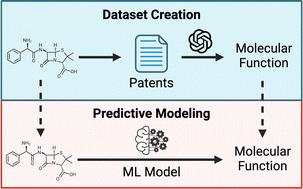
The fundamental goal of small molecule discovery is to generate chemicals with target functionality. While this often proceeds through structure-based methods, we set out to investigate the practicality of methods that leverage the extensive corpus of chemical literature. We hypothesize that a sufficiently large text-derived chemical function dataset would mirror the actual landscape of chemical functionality. Such a landscape would implicitly capture complex physical and biological interactions given that chemical function arises from both a molecule's structure and its interacting partners. To evaluate this hypothesis, we built a Chemical Function (CheF) dataset of patent-derived functional labels. This dataset, comprising 631 K molecule–function pairs, was created using an LLM- and embedding-based method to obtain 1.5 K unique functional labels for approximately 100 K randomly selected molecules from their corresponding 188 K unique patents. We carry out a series of analyses demonstrating that the CheF dataset contains a semantically coherent textual representation of the functional landscape congruent with chemical structural relationships, thus approximating the actual chemical function landscape. We then demonstrate through several examples that this text-based functional landscape can be leveraged to identify drugs with target functionality using a model able to predict functional profiles from structure alone. We believe that functional label-guided molecular discovery may serve as an alternative approach to traditional structure-based methods in the pursuit of designing novel functional molecules.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


