Johan Lela Andika, Anis Salwa Mohd Khairuddin, Harikrishnan Ramiah, Jeevan Kanesan
{"title":"Improved feature extraction network in lightweight YOLOv7 model for real-time vehicle detection on low-cost hardware","authors":"Johan Lela Andika, Anis Salwa Mohd Khairuddin, Harikrishnan Ramiah, Jeevan Kanesan","doi":"10.1007/s11554-024-01457-1","DOIUrl":null,"url":null,"abstract":"<p>The advancement of unmanned aerial vehicles (UAVs) has drawn researchers to update object detection algorithms for better accuracy and computation performance. Previous works applying deep learning models for object detection applications required high graphics processing unit (GPU) computation power. Generally, object detection models suffer trade-off between accuracy and model size where the relationship is not always linear in deep learning models. Various factors such as architectural design, optimization techniques, and dataset characteristics can significantly influence the accuracy, model size, and computation cost in adopting object detection models for low-cost embedded devices. Hence, it is crucial to employ lightweight object detection models for real-time object identification for the solution to be sustainable. In this work, an improved feature extraction network is proposed by incorporating an efficient long-range aggregation network for vehicle detection (ELAN-VD) in the backbone layer. The architecture improvement in YOLOv7-tiny model is proposed to improve the accuracy of detecting small vehicles in the aerial image. Besides that, the image size output of the second and third prediction boxes is upscaled for better performance. This study showed that the proposed method yields a mean average precision (mAP) of 57.94%, which is higher than that of the conventional YOLOv7-tiny. In addition, the proposed model showed significant performance when compared to previous works, making it viable for application in low-cost embedded devices.</p>","PeriodicalId":51224,"journal":{"name":"Journal of Real-Time Image Processing","volume":"1 1","pages":""},"PeriodicalIF":2.9000,"publicationDate":"2024-04-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Real-Time Image Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11554-024-01457-1","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
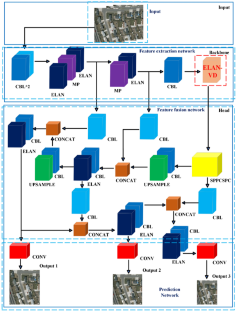
The advancement of unmanned aerial vehicles (UAVs) has drawn researchers to update object detection algorithms for better accuracy and computation performance. Previous works applying deep learning models for object detection applications required high graphics processing unit (GPU) computation power. Generally, object detection models suffer trade-off between accuracy and model size where the relationship is not always linear in deep learning models. Various factors such as architectural design, optimization techniques, and dataset characteristics can significantly influence the accuracy, model size, and computation cost in adopting object detection models for low-cost embedded devices. Hence, it is crucial to employ lightweight object detection models for real-time object identification for the solution to be sustainable. In this work, an improved feature extraction network is proposed by incorporating an efficient long-range aggregation network for vehicle detection (ELAN-VD) in the backbone layer. The architecture improvement in YOLOv7-tiny model is proposed to improve the accuracy of detecting small vehicles in the aerial image. Besides that, the image size output of the second and third prediction boxes is upscaled for better performance. This study showed that the proposed method yields a mean average precision (mAP) of 57.94%, which is higher than that of the conventional YOLOv7-tiny. In addition, the proposed model showed significant performance when compared to previous works, making it viable for application in low-cost embedded devices.
期刊介绍:
Due to rapid advancements in integrated circuit technology, the rich theoretical results that have been developed by the image and video processing research community are now being increasingly applied in practical systems to solve real-world image and video processing problems. Such systems involve constraints placed not only on their size, cost, and power consumption, but also on the timeliness of the image data processed.
Examples of such systems are mobile phones, digital still/video/cell-phone cameras, portable media players, personal digital assistants, high-definition television, video surveillance systems, industrial visual inspection systems, medical imaging devices, vision-guided autonomous robots, spectral imaging systems, and many other real-time embedded systems. In these real-time systems, strict timing requirements demand that results are available within a certain interval of time as imposed by the application.
It is often the case that an image processing algorithm is developed and proven theoretically sound, presumably with a specific application in mind, but its practical applications and the detailed steps, methodology, and trade-off analysis required to achieve its real-time performance are not fully explored, leaving these critical and usually non-trivial issues for those wishing to employ the algorithm in a real-time system.
The Journal of Real-Time Image Processing is intended to bridge the gap between the theory and practice of image processing, serving the greater community of researchers, practicing engineers, and industrial professionals who deal with designing, implementing or utilizing image processing systems which must satisfy real-time design constraints.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


