Faux Hate: unravelling the web of fake narratives in spreading hateful stories: a multi-label and multi-class dataset in cross-lingual Hindi-English code-mixed text
IF 1.8 3区 计算机科学Q3 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
{"title":"Faux Hate: unravelling the web of fake narratives in spreading hateful stories: a multi-label and multi-class dataset in cross-lingual Hindi-English code-mixed text","authors":"Shankar Biradar, Sunil Saumya, Arun Chauhan","doi":"10.1007/s10579-024-09732-0","DOIUrl":null,"url":null,"abstract":"<p>Social media has undeniably transformed the way people communicate; however, it also comes with unquestionable drawbacks, notably the proliferation of fake and hateful comments. Recent observations have indicated that these two issues often coexist, with discussions on hate topics frequently being dominated by the fake. Therefore, it has become imperative to explore the role of fake narratives in the dissemination of hate in contemporary times. In this direction, the proposed article introduces a novel data set known as the Faux Hate Multi-Label Data set (FHMLD) comprising 8014 fake-instigated hateful comments in Hindi-English code-mixed text. To the best of our knowledge, this marks the first endeavour to bring together both fake and hateful content within a unified framework. Further, the proposed data set is collected from diverse platforms such as YouTube and Twitter to mitigate user-associated bias. To investigate a relation between the presence of fake narratives and its impact on the intensity of the hate, this study presents a statistical analysis using the Chi-square test. The statistical findings indicate that the calculated <span>\\(\\chi ^2\\)</span> value is greater than the value from the standard table, leading to the rejection of the null hypothesis. Additionally, the current study present baseline methods for categorizing multi-class and multi-label data set, utilizing syntactical and semantic features at both word and sentence levels. The experimental results demonstrate that the fastText and SVM based method outperforms others models with an accuracy of 71% and 58% for binary fake–hate and severity prediction respectively.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"38 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-04-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-024-09732-0","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
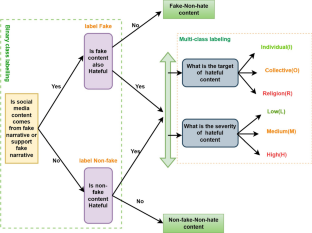
Social media has undeniably transformed the way people communicate; however, it also comes with unquestionable drawbacks, notably the proliferation of fake and hateful comments. Recent observations have indicated that these two issues often coexist, with discussions on hate topics frequently being dominated by the fake. Therefore, it has become imperative to explore the role of fake narratives in the dissemination of hate in contemporary times. In this direction, the proposed article introduces a novel data set known as the Faux Hate Multi-Label Data set (FHMLD) comprising 8014 fake-instigated hateful comments in Hindi-English code-mixed text. To the best of our knowledge, this marks the first endeavour to bring together both fake and hateful content within a unified framework. Further, the proposed data set is collected from diverse platforms such as YouTube and Twitter to mitigate user-associated bias. To investigate a relation between the presence of fake narratives and its impact on the intensity of the hate, this study presents a statistical analysis using the Chi-square test. The statistical findings indicate that the calculated \(\chi ^2\) value is greater than the value from the standard table, leading to the rejection of the null hypothesis. Additionally, the current study present baseline methods for categorizing multi-class and multi-label data set, utilizing syntactical and semantic features at both word and sentence levels. The experimental results demonstrate that the fastText and SVM based method outperforms others models with an accuracy of 71% and 58% for binary fake–hate and severity prediction respectively.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


