{"title":"Pure Vision Transformer (CT-ViT) with Noise2Neighbors Interpolation for Low-Dose CT Image Denoising","authors":"Luella Marcos, Paul Babyn, Javad Alirezaie","doi":"10.1007/s10278-024-01108-8","DOIUrl":null,"url":null,"abstract":"<p>Convolutional neural networks (CNN) have been used for a wide variety of deep learning applications, especially in computer vision. For medical image processing, researchers have identified certain challenges associated with CNNs. These challenges encompass the generation of less informative features, limitations in capturing both high and low-frequency information within feature maps, and the computational cost incurred when enhancing receptive fields by deepening the network. Transformers have emerged as an approach aiming to address and overcome these specific limitations of CNNs in the context of medical image analysis. Preservation of all spatial details of medical images is necessary to ensure accurate patient diagnosis. Hence, this research introduced the use of a pure Vision Transformer (ViT) for a denoising artificial neural network for medical image processing specifically for low-dose computed tomography (LDCT) image denoising. The proposed model follows a U-Net framework that contains ViT modules with the integration of Noise2Neighbor (N2N) interpolation operation. Five different datasets containing LDCT and normal-dose CT (NDCT) image pairs were used to carry out this experiment. To test the efficacy of the proposed model, this experiment includes comparisons between the quantitative and visual results among CNN-based (BM3D, RED-CNN, DRL-E-MP), hybrid CNN-ViT-based (TED-Net), and the proposed pure ViT-based denoising model. The findings of this study showed that there is about 15–20% increase in SSIM and PSNR when using self-attention transformers than using the typical pure CNN. Visual results also showed improvements especially when it comes to showing fine structural details of CT images.</p>","PeriodicalId":50214,"journal":{"name":"Journal of Digital Imaging","volume":"2 1","pages":""},"PeriodicalIF":3.8000,"publicationDate":"2024-04-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Digital Imaging","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1007/s10278-024-01108-8","RegionNum":2,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
引用次数: 0
Abstract
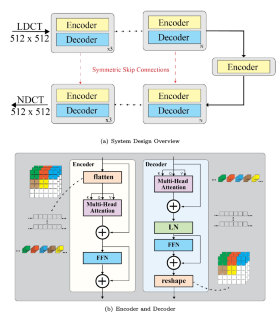
Convolutional neural networks (CNN) have been used for a wide variety of deep learning applications, especially in computer vision. For medical image processing, researchers have identified certain challenges associated with CNNs. These challenges encompass the generation of less informative features, limitations in capturing both high and low-frequency information within feature maps, and the computational cost incurred when enhancing receptive fields by deepening the network. Transformers have emerged as an approach aiming to address and overcome these specific limitations of CNNs in the context of medical image analysis. Preservation of all spatial details of medical images is necessary to ensure accurate patient diagnosis. Hence, this research introduced the use of a pure Vision Transformer (ViT) for a denoising artificial neural network for medical image processing specifically for low-dose computed tomography (LDCT) image denoising. The proposed model follows a U-Net framework that contains ViT modules with the integration of Noise2Neighbor (N2N) interpolation operation. Five different datasets containing LDCT and normal-dose CT (NDCT) image pairs were used to carry out this experiment. To test the efficacy of the proposed model, this experiment includes comparisons between the quantitative and visual results among CNN-based (BM3D, RED-CNN, DRL-E-MP), hybrid CNN-ViT-based (TED-Net), and the proposed pure ViT-based denoising model. The findings of this study showed that there is about 15–20% increase in SSIM and PSNR when using self-attention transformers than using the typical pure CNN. Visual results also showed improvements especially when it comes to showing fine structural details of CT images.
期刊介绍:
The Journal of Digital Imaging (JDI) is the official peer-reviewed journal of the Society for Imaging Informatics in Medicine (SIIM). JDI’s goal is to enhance the exchange of knowledge encompassed by the general topic of Imaging Informatics in Medicine such as research and practice in clinical, engineering, and information technologies and techniques in all medical imaging environments. JDI topics are of interest to researchers, developers, educators, physicians, and imaging informatics professionals.
Suggested Topics
PACS and component systems; imaging informatics for the enterprise; image-enabled electronic medical records; RIS and HIS; digital image acquisition; image processing; image data compression; 3D, visualization, and multimedia; speech recognition; computer-aided diagnosis; facilities design; imaging vocabularies and ontologies; Transforming the Radiological Interpretation Process (TRIP™); DICOM and other standards; workflow and process modeling and simulation; quality assurance; archive integrity and security; teleradiology; digital mammography; and radiological informatics education.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


