Quantitative text analysis
IF 50.1
Q1 MULTIDISCIPLINARY SCIENCES
引用次数: 0
Abstract
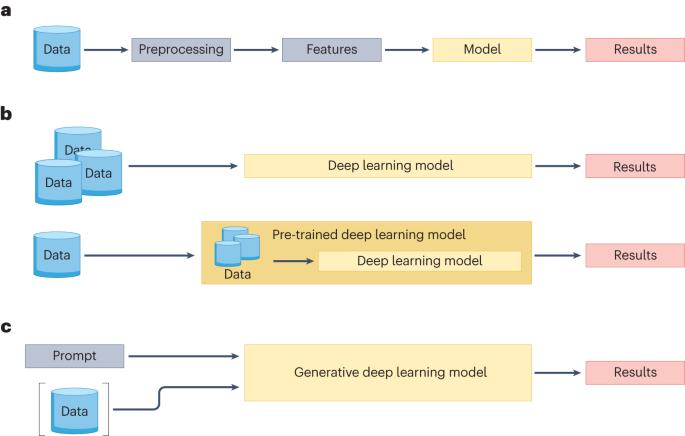
Text analysis has undergone substantial evolution since its inception, moving from manual qualitative assessments to sophisticated quantitative and computational methods. Beginning in the late twentieth century, a surge in the utilization of computational techniques reshaped the landscape of text analysis, catalysed by advances in computational power and database technologies. Researchers in various fields, from history to medicine, are now using quantitative methodologies, particularly machine learning, to extract insights from massive textual data sets. This transformation can be described in three discernible methodological stages: feature-based models, representation learning models and generative models. Although sequential, these stages are complementary, each addressing analytical challenges in the text analysis. The progression from feature-based models that require manual feature engineering to contemporary generative models, such as GPT-4 and Llama2, signifies a change in the workflow, scale and computational infrastructure of the quantitative text analysis. This Primer presents a detailed introduction of some of these developments, offering insights into the methods, principles and applications pertinent to researchers embarking on the quantitative text analysis, especially within the field of machine learning. Quantitative text analysis is a range of computational methods to analyse text data statistically and mathematically. In this Primer, Kristoffer Nielbo et al. introduce the methods, principles and applications of the quantitative text analysis across disciplines.
定量文本分析
文本分析自诞生以来经历了巨大的演变,从人工定性评估发展到复杂的定量和计算方法。从二十世纪末开始,在计算能力和数据库技术进步的推动下,计算技术的使用激增,重塑了文本分析的格局。现在,从历史到医学等各个领域的研究人员都在使用定量方法,特别是机器学习,从海量文本数据集中提取见解。这种转变可分为三个明显的方法论阶段:基于特征的模型、表征学习模型和生成模型。这些阶段虽有先后之分,但却相辅相成,各自解决了文本分析中的分析难题。从需要人工特征工程的基于特征的模型到当代的生成模型(如 GPT-4 和 Llama2),标志着定量文本分析的工作流程、规模和计算基础设施发生了变化。本《入门指南》详细介绍了其中的一些发展,为着手进行定量文本分析的研究人员,尤其是机器学习领域的研究人员,提供了有关方法、原理和应用的见解。文本定量分析是对文本数据进行统计和数学分析的一系列计算方法。在这本《入门》中,Kristoffer Nielbo 等人介绍了跨学科的定量文本分析方法、原理和应用。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


