Kanhai S Amin, Linda C Mayes, Pavan Khosla, Rushabh H Doshi
{"title":"Assessing the Efficacy of Large Language Models in Health Literacy: A Comprehensive Cross-Sectional Study.","authors":"Kanhai S Amin, Linda C Mayes, Pavan Khosla, Rushabh H Doshi","doi":"10.59249/ZTOZ1966","DOIUrl":null,"url":null,"abstract":"<p><p>Enhanced health literacy in children has been empirically linked to better health outcomes over the long term; however, few interventions have been shown to improve health literacy. In this context, we investigate whether large language models (LLMs) can serve as a medium to improve health literacy in children. We tested pediatric conditions using 26 different prompts in ChatGPT-3.5, ChatGPT-4, Microsoft Bing, and Google Bard (now known as Google Gemini). The primary outcome measurement was the reading grade level (RGL) of output as assessed by Gunning Fog, Flesch-Kincaid Grade Level, Automated Readability Index, and Coleman-Liau indices. Word counts were also assessed. Across all models, output for basic prompts such as \"Explain\" and \"What is (are),\" were at, or exceeded, the tenth-grade RGL. When prompts were specified to explain conditions from the first- to twelfth-grade level, we found that LLMs had varying abilities to tailor responses based on grade level. ChatGPT-3.5 provided responses that ranged from the seventh-grade to college freshmen RGL while ChatGPT-4 outputted responses from the tenth-grade to the college senior RGL. Microsoft Bing provided responses from the ninth- to eleventh-grade RGL while Google Bard provided responses from the seventh- to tenth-grade RGL. LLMs face challenges in crafting outputs below a sixth-grade RGL. However, their capability to modify outputs above this threshold, provides a potential mechanism for adolescents to explore, understand, and engage with information regarding their health conditions, spanning from simple to complex terms. Future studies are needed to verify the accuracy and efficacy of these tools.</p>","PeriodicalId":48617,"journal":{"name":"Yale Journal of Biology and Medicine","volume":"97 1","pages":"17-27"},"PeriodicalIF":3.9000,"publicationDate":"2024-03-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10964816/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Yale Journal of Biology and Medicine","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.59249/ZTOZ1966","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/3/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
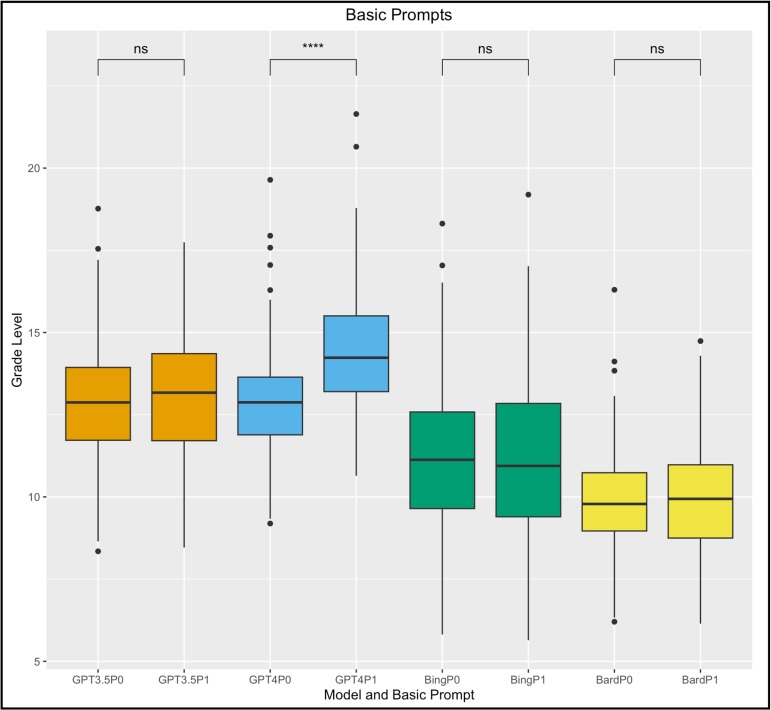
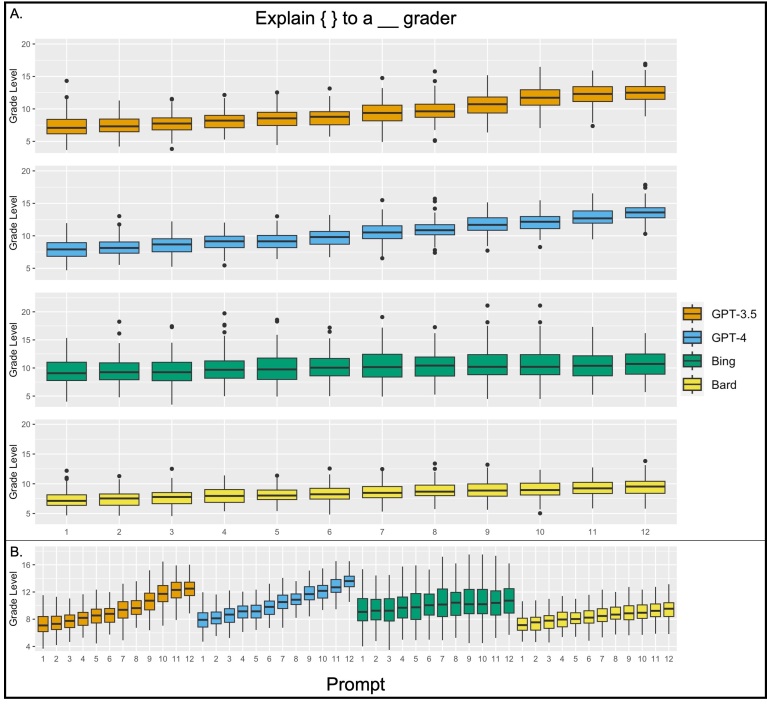
Enhanced health literacy in children has been empirically linked to better health outcomes over the long term; however, few interventions have been shown to improve health literacy. In this context, we investigate whether large language models (LLMs) can serve as a medium to improve health literacy in children. We tested pediatric conditions using 26 different prompts in ChatGPT-3.5, ChatGPT-4, Microsoft Bing, and Google Bard (now known as Google Gemini). The primary outcome measurement was the reading grade level (RGL) of output as assessed by Gunning Fog, Flesch-Kincaid Grade Level, Automated Readability Index, and Coleman-Liau indices. Word counts were also assessed. Across all models, output for basic prompts such as "Explain" and "What is (are)," were at, or exceeded, the tenth-grade RGL. When prompts were specified to explain conditions from the first- to twelfth-grade level, we found that LLMs had varying abilities to tailor responses based on grade level. ChatGPT-3.5 provided responses that ranged from the seventh-grade to college freshmen RGL while ChatGPT-4 outputted responses from the tenth-grade to the college senior RGL. Microsoft Bing provided responses from the ninth- to eleventh-grade RGL while Google Bard provided responses from the seventh- to tenth-grade RGL. LLMs face challenges in crafting outputs below a sixth-grade RGL. However, their capability to modify outputs above this threshold, provides a potential mechanism for adolescents to explore, understand, and engage with information regarding their health conditions, spanning from simple to complex terms. Future studies are needed to verify the accuracy and efficacy of these tools.
期刊介绍:
The Yale Journal of Biology and Medicine (YJBM) is a graduate and medical student-run, peer-reviewed, open-access journal dedicated to the publication of original research articles, scientific reviews, articles on medical history, personal perspectives on medicine, policy analyses, case reports, and symposia related to biomedical matters. YJBM is published quarterly and aims to publish articles of interest to both physicians and scientists. YJBM is and has been an internationally distributed journal with a long history of landmark articles. Our contributors feature a notable list of philosophers, statesmen, scientists, and physicians, including Ernst Cassirer, Harvey Cushing, Rene Dubos, Edward Kennedy, Donald Seldin, and Jack Strominger. Our Editorial Board consists of students and faculty members from Yale School of Medicine and Yale University Graduate School of Arts & Sciences. All manuscripts submitted to YJBM are first evaluated on the basis of scientific quality, originality, appropriateness, contribution to the field, and style. Suitable manuscripts are then subject to rigorous, fair, and rapid peer review.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


