{"title":"ChatGPT Yields a Passing Score on a Pediatric Board Preparatory Exam but Raises Red Flags.","authors":"Mindy Le, Michael Davis","doi":"10.1177/2333794X241240327","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>We aimed to evaluate the performance of a publicly-available online artificial intelligence program (OpenAI's ChatGPT-3.5 and -4.0, August 3 versions) on a pediatric board preparatory examination, 2021 and 2022 PREP<sup>®</sup> Self-Assessment, American Academy of Pediatrics (AAP).</p><p><strong>Methods: </strong>We entered 245 questions and answer choices from the Pediatrics 2021 PREP<sup>®</sup> Self-Assessment and 247 questions and answer choices from the Pediatrics 2022 PREP<sup>®</sup> Self-Assessment into OpenAI's ChatGPT-3.5 and ChatGPT-4.0, August 3 versions, in September 2023. The ChatGPT-3.5 and 4.0 scores were compared with the advertised passing scores (70%+) for the PREP<sup>®</sup> exams and the average scores (74.09%) and (75.71%) for all 10 715 and 6825 first-time human test takers.</p><p><strong>Results: </strong>For the AAP 2021 and 2022 PREP<sup>®</sup> Self-Assessments, ChatGPT-3.5 answered 143 of 243 (58.85%) and 137 of 247 (55.46%) questions correctly on a single attempt. ChatGPT-4.0 answered 193 of 243 (79.84%) and 208 of 247 (84.21%) questions correctly.</p><p><strong>Conclusion: </strong>Using a publicly-available online chatbot to answer pediatric board preparatory examination questions yielded a passing score but demonstrated significant limitations in the chatbot's ability to assess some complex medical situations in children, posing a potential risk to this vulnerable population.</p>","PeriodicalId":12576,"journal":{"name":"Global Pediatric Health","volume":"11 ","pages":"2333794X241240327"},"PeriodicalIF":1.4000,"publicationDate":"2024-03-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10962030/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Global Pediatric Health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/2333794X241240327","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"PEDIATRICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: We aimed to evaluate the performance of a publicly-available online artificial intelligence program (OpenAI's ChatGPT-3.5 and -4.0, August 3 versions) on a pediatric board preparatory examination, 2021 and 2022 PREP® Self-Assessment, American Academy of Pediatrics (AAP).
Methods: We entered 245 questions and answer choices from the Pediatrics 2021 PREP® Self-Assessment and 247 questions and answer choices from the Pediatrics 2022 PREP® Self-Assessment into OpenAI's ChatGPT-3.5 and ChatGPT-4.0, August 3 versions, in September 2023. The ChatGPT-3.5 and 4.0 scores were compared with the advertised passing scores (70%+) for the PREP® exams and the average scores (74.09%) and (75.71%) for all 10 715 and 6825 first-time human test takers.
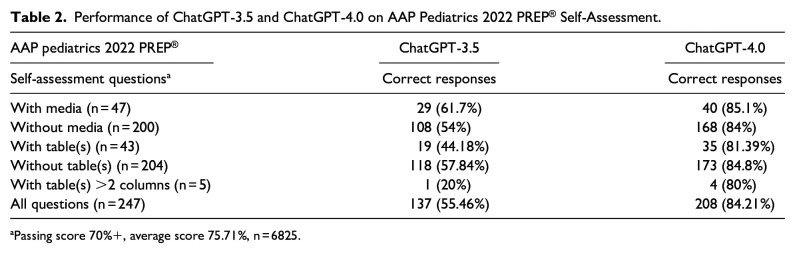
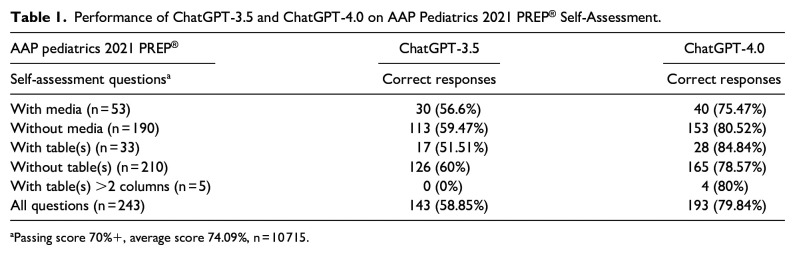
Results: For the AAP 2021 and 2022 PREP® Self-Assessments, ChatGPT-3.5 answered 143 of 243 (58.85%) and 137 of 247 (55.46%) questions correctly on a single attempt. ChatGPT-4.0 answered 193 of 243 (79.84%) and 208 of 247 (84.21%) questions correctly.
Conclusion: Using a publicly-available online chatbot to answer pediatric board preparatory examination questions yielded a passing score but demonstrated significant limitations in the chatbot's ability to assess some complex medical situations in children, posing a potential risk to this vulnerable population.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


