Boosting court judgment prediction and explanation using legal entities
Abstract
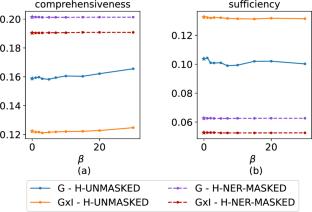
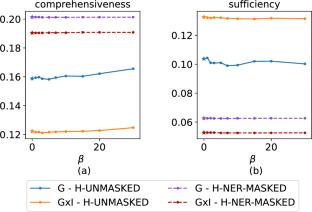
The automatic prediction of court case judgments using Deep Learning and Natural Language Processing is challenged by the variety of norms and regulations, the inherent complexity of the forensic language, and the length of legal judgments. Although state-of-the-art transformer-based architectures and Large Language Models (LLMs) are pre-trained on large-scale datasets, the underlying model reasoning is not transparent to the legal expert. This paper jointly addresses court judgment prediction and explanation by not only predicting the judgment but also providing legal experts with sentence-based explanations. To boost the performance of both tasks we leverage a legal named entity recognition step, which automatically annotates documents with meaningful domain-specific entity tags and masks the corresponding fine-grained descriptions. In such a way, transformer-based architectures and Large Language Models can attend to in-domain entity-related information in the inference process while neglecting irrelevant details. Furthermore, the explainer can boost the relevance of entity-enriched sentences while limiting the diffusion of potentially sensitive information. We also explore the use of in-context learning and lightweight fine-tuning to tailor LLMs to the legal language style and the downstream prediction and explanation tasks. The results obtained on a benchmark dataset from the Indian judicial system show the superior performance of entity-aware approaches to both judgment prediction and explanation.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


