{"title":"Improving model choice in classification: an approach based on clustering of covariance matrices","authors":"David Rodríguez-Vítores, Carlos Matrán","doi":"10.1007/s11222-024-10410-y","DOIUrl":null,"url":null,"abstract":"<p>This work introduces a refinement of the Parsimonious Model for fitting a Gaussian Mixture. The improvement is based on the consideration of clusters of the involved covariance matrices according to a criterion, such as sharing Principal Directions. This and other similarity criteria that arise from the spectral decomposition of a matrix are the bases of the Parsimonious Model. We show that such groupings of covariance matrices can be achieved through simple modifications of the CEM (Classification Expectation Maximization) algorithm. Our approach leads to propose Gaussian Mixture Models for model-based clustering and discriminant analysis, in which covariance matrices are clustered according to a parsimonious criterion, creating intermediate steps between the fourteen widely known parsimonious models. The added versatility not only allows us to obtain models with fewer parameters for fitting the data, but also provides greater interpretability. We show its usefulness for model-based clustering and discriminant analysis, providing algorithms to find approximate solutions verifying suitable size, shape and orientation constraints, and applying them to both simulation and real data examples.</p>","PeriodicalId":22058,"journal":{"name":"Statistics and Computing","volume":"99 1","pages":""},"PeriodicalIF":1.6000,"publicationDate":"2024-03-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Statistics and Computing","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s11222-024-10410-y","RegionNum":2,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
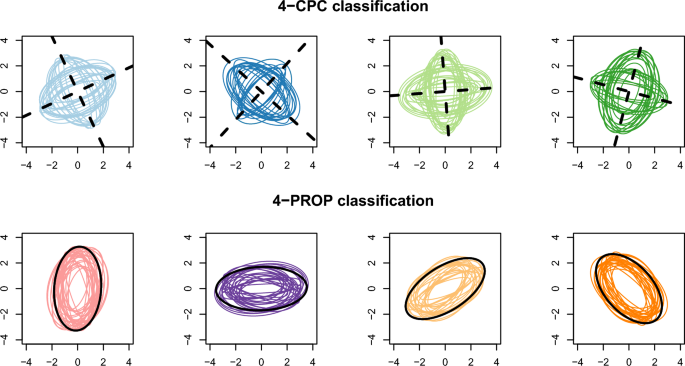
This work introduces a refinement of the Parsimonious Model for fitting a Gaussian Mixture. The improvement is based on the consideration of clusters of the involved covariance matrices according to a criterion, such as sharing Principal Directions. This and other similarity criteria that arise from the spectral decomposition of a matrix are the bases of the Parsimonious Model. We show that such groupings of covariance matrices can be achieved through simple modifications of the CEM (Classification Expectation Maximization) algorithm. Our approach leads to propose Gaussian Mixture Models for model-based clustering and discriminant analysis, in which covariance matrices are clustered according to a parsimonious criterion, creating intermediate steps between the fourteen widely known parsimonious models. The added versatility not only allows us to obtain models with fewer parameters for fitting the data, but also provides greater interpretability. We show its usefulness for model-based clustering and discriminant analysis, providing algorithms to find approximate solutions verifying suitable size, shape and orientation constraints, and applying them to both simulation and real data examples.
期刊介绍:
Statistics and Computing is a bi-monthly refereed journal which publishes papers covering the range of the interface between the statistical and computing sciences.
In particular, it addresses the use of statistical concepts in computing science, for example in machine learning, computer vision and data analytics, as well as the use of computers in data modelling, prediction and analysis. Specific topics which are covered include: techniques for evaluating analytically intractable problems such as bootstrap resampling, Markov chain Monte Carlo, sequential Monte Carlo, approximate Bayesian computation, search and optimization methods, stochastic simulation and Monte Carlo, graphics, computer environments, statistical approaches to software errors, information retrieval, machine learning, statistics of databases and database technology, huge data sets and big data analytics, computer algebra, graphical models, image processing, tomography, inverse problems and uncertainty quantification.
In addition, the journal contains original research reports, authoritative review papers, discussed papers, and occasional special issues on particular topics or carrying proceedings of relevant conferences. Statistics and Computing also publishes book review and software review sections.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


